
LLM 추론의 두 단계: Prefill과 Decode
Prefill (프리필) 단계
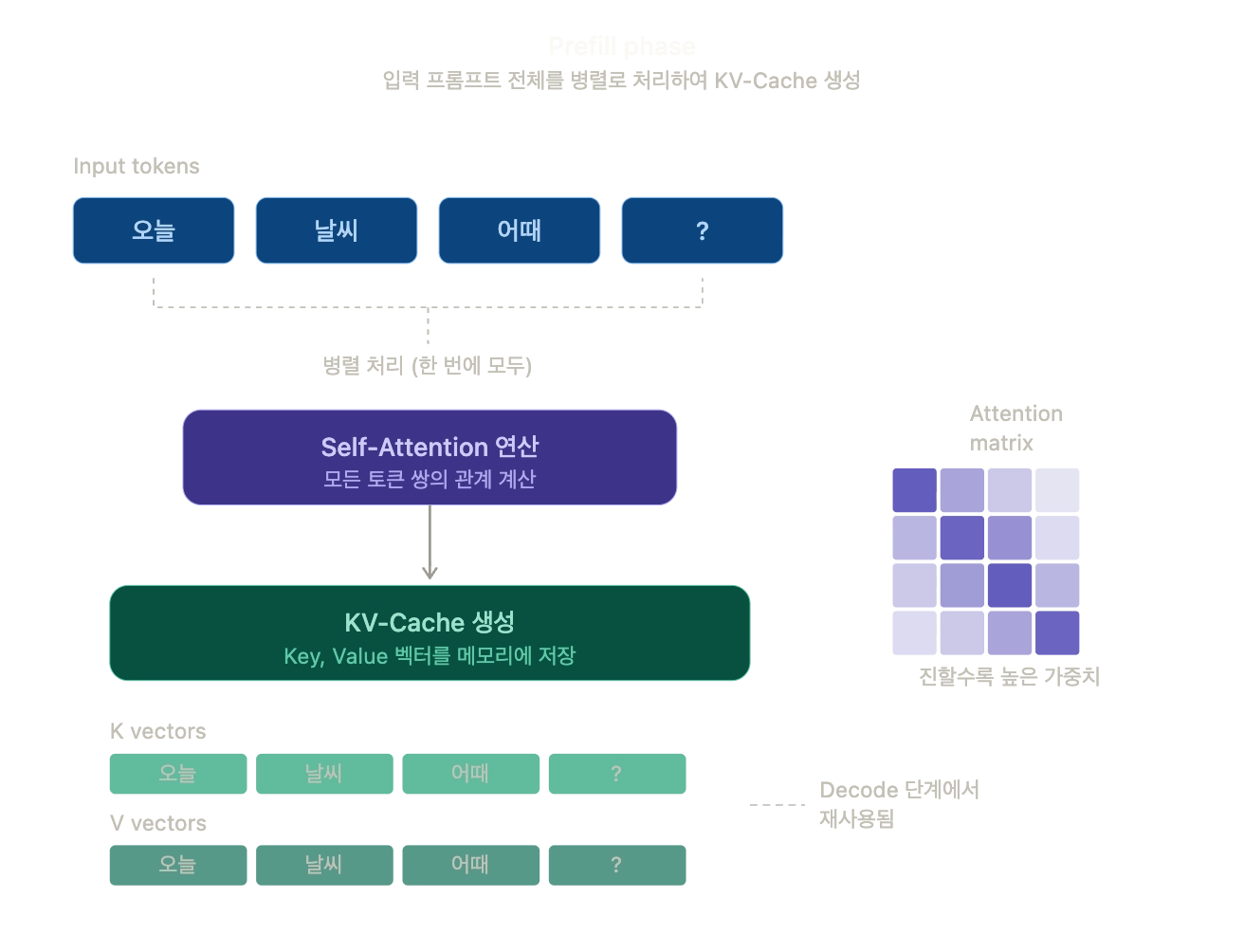
Prefill은 사용자가 입력한 프롬프트를 한꺼번에 병렬로 처리하는 단계입니다. "오늘 날씨 어때?"라는 4개의 토큰이 들어오면, 이 토큰들을 순차적으로 하나씩 보는 게 아니라 동시에 Self-Attention 연산을 수행합니다.
핵심은 이 과정에서 KV-Cache가 만들어진다는 점입니다. 각 토큰에 대해 Key 벡터와 Value 벡터를 계산해서 GPU 메모리에 저장해두면, 이후 Decode 단계에서 이 값들을 다시 계산할 필요 없이 꺼내 쓸 수 있습니다.
Attention 행렬을 보면 모든 토큰 쌍 (i, j)에 대해 가중치를 계산하므로, 입력 길이 n에 대해 연산 복잡도는 O(n²) 입니다. 프롬프트가 길수록 이 단계가 오래 걸리고, 이것이 곧 TTFT가 커지는 직접적인 원인입니다.
이 단계는 compute-bound(연산량 제한)입니다.
GPU의 연산 코어를 최대한 활용하는 구간이라, 배치 크기나 텐서 병렬화 같은 전략이 Prefill 성능에 큰 영향을 줍니다.
Decode (디코딩) 단계
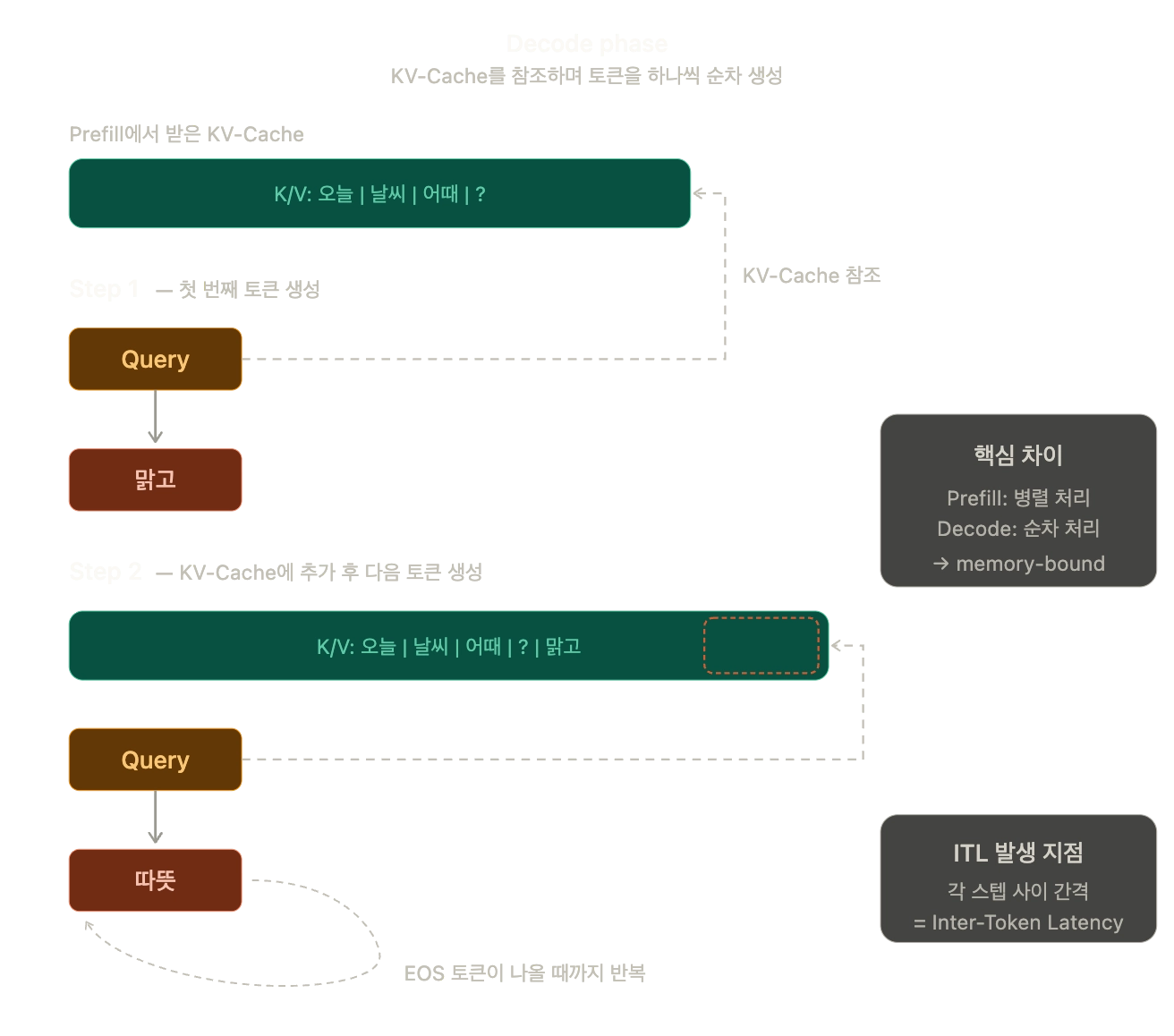
Decode는 Prefill 에서 만든 KV-Cache를 기반으로 토큰을 하나씩 생성하는 자기회귀(autoregressive) 루프입니다.
동작 흐름은 이렇습니다.
새로 생성할 토큰에 대해 Query 벡터만 계산하고, 이전까지 누적된 KV-Cache의 Key/Value를 참조해서 Attention을 수행합니다. 토큰이 하나 나오면 그 토큰의 K/V를 캐시에 추가하고, 다시 다음 토큰을 생성합니다. EOS(End of Sequence) 토큰이 나올 때까지 이 루프를 반복합니다.
Prefill과의 결정적인 차이는 병목 지점입니다. Prefill 은 한꺼번에 대량 연산을 돌리니까 compute-bound이지만, Decode는 매 스텝마다 토큰 1개만 처리하면서 점점 커지는 KV-Cache를 GPU 메모리에서 읽어와야 하므로 memory-bandwidth-bound 입니다.
연산량 자체는 적은데, 메모리에서 데이터를 가져오는 대역폭이 병목이 됩니다.
그래서 출력이 길어질수록 KV-Cache 크기가 O(n_input + n_generated) 로 커지고, 매 스텝마다 읽어야 할 메모리 양이 늘어나면서 ITL이 점점 나빠질 수 있습니다. 이걸 일정하게 유지하는 게 서빙 최적화의 핵심 과제입니다.
LLM 성능의 모니터링 기준
Prefill과 Decode의 구조를 이해했으니, 이제 이 두 단계를 어떤 숫자로 감시하고 판단할 것인가가 문제입니다.
LLM 추론 서빙은 기존 웹 서비스와 근본적으로 다릅니다. 일반 API는 요청-응답이 1회인데, LLM은 한 번의 요청에 대해 토큰이 수십~수백 개 연속으로 생성됩니다. 그래서 기존의 latency, throughput 개념을 그대로 쓸 수 없고, Prefill 구간과 Decode 구간을 분리해서 측정하는 전용 메트릭이 필요합니다.
아래에서 다루는 지표들은 각각 Prefill 또는 Decode 중 어디에 대한 것인지가 명확합니다.
| 메트릭 | 주로 반영하는 단계 | 핵심 질문 |
|---|---|---|
| TTFT | Prefill | 사용자가 첫 응답을 얼마나 기다리는가? |
| ITL / TPOT | Decode | 토큰이 얼마나 빠르게 이어서 나오는가? |
| Latency | Prefill + Decode | 전체 응답을 받기까지 총 얼마 걸리는가? |
| TPS | Decode (시스템 관점) | 시스템이 초당 몇 토큰을 뱉는가? |
| RPS | 전체 파이프라인 | 시스템이 초당 몇 개의 요청을 완료하는가? |
| Cache Hit | Prefill 최적화 | KV-Cache 재사용으로 Prefill을 얼마나 줄였는가? |
이제 각 지표를 하나씩 살펴보겠습니다.
TTFT (Time to First Token)
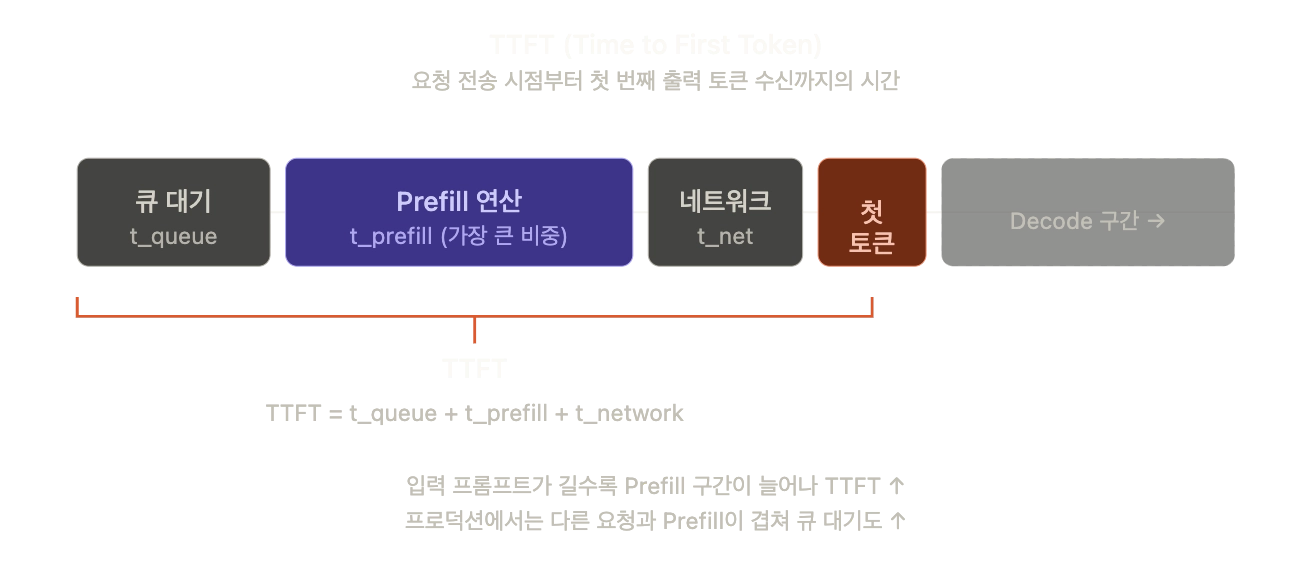
사용자가 요청을 보낸 순간부터 첫 번째 출력 토큰을 받기까지의 시간입니다. 체감 반응 속도 그 자체라서 챗봇이나 실시간 서비스에서 가장 먼저 보는 지표입니다.
세 구간 중 Prefill이 지배적입니다. Attention의 O(n²) 연산이 여기서 일어나기 때문에, 프롬프트가 길면 TTFT가 급격히 올라갑니다. 프로덕션 환경에서는 동시 요청 때문에 큐 대기 시간까지 붙습니다.
주의: GenAI-Perf와 LLMPerf 모두, 내용이 비어 있는(토큰이 없는) 초기 응답은 TTFT 측정에서 제외합니다.
Latency
요청을 보낸 시점부터 마지막 토큰을 수신하기까지의 전체 소요 시간입니다.
큐잉, 배칭, 네트워크 지연을 모두 포함합니다.
여기서 Generation Time은 첫 번째 토큰 수신 시점 t₁부터 마지막 토큰 수신 시점 tₙ까지의 시간입니다.
SLA(Service Level Agreement) 기반 서비스에서 가장 기본이 되는 전체 응답 시간 지표입니다.
스트리밍 모드에서는 부분 결과가 반환될 때마다 de-tokenization이 여러 번 수행되며, GenAI-Perf는 마지막 [done] 시그널이나 빈 응답을 latency 계산에서 제외합니다.
ITL (Inter-Token Latency) / TPOT (Time Per Output Token)
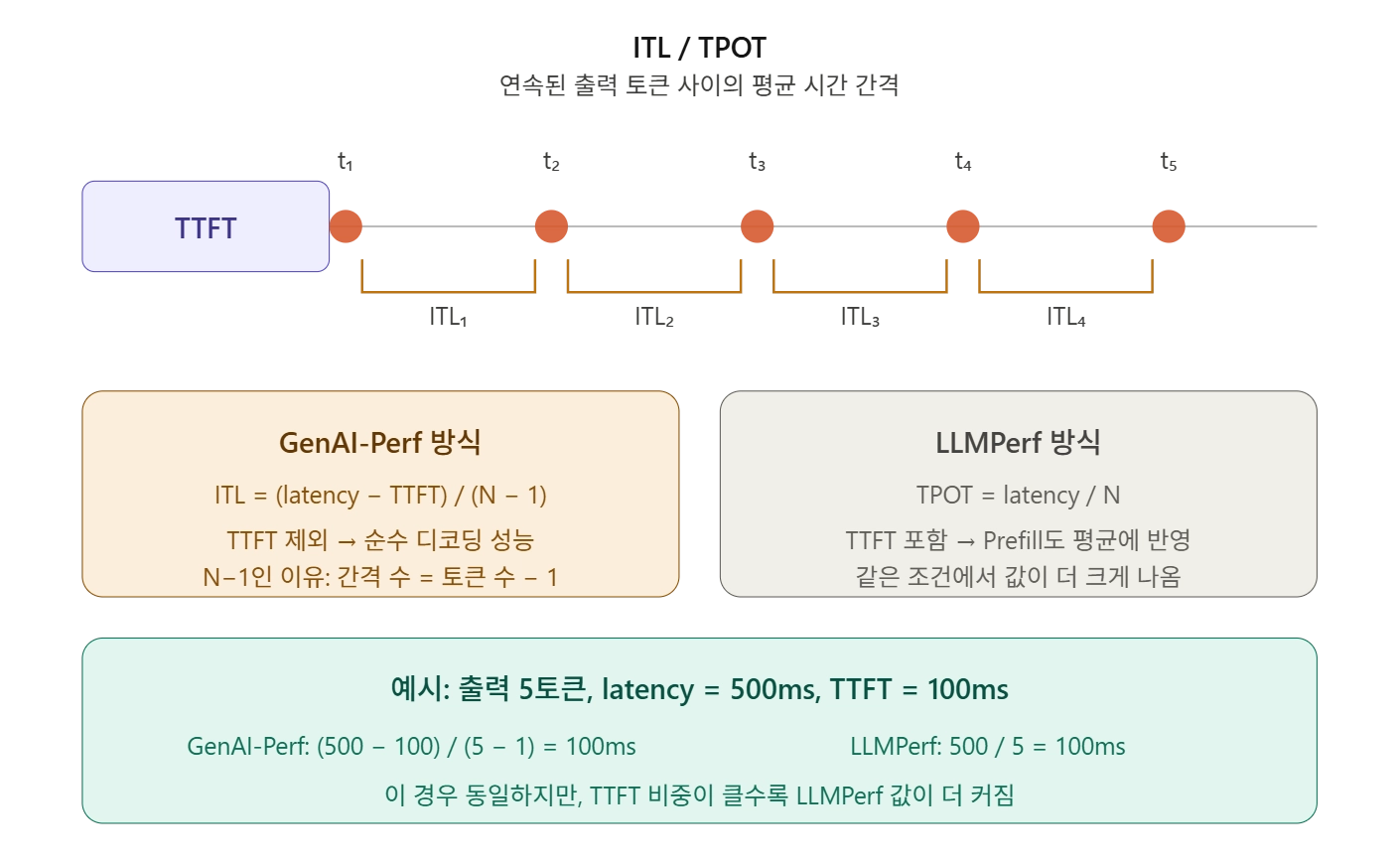
정의: 연속된 출력 토큰 사이의 평균 시간 간격입니다. 스트리밍 UX에서 "글자가 얼마나 빠르게 이어서 나오는가"를 결정합니다.
출력 토큰이 시점 t₁, t₂, …, tₙ에 수신된다면, 개별 토큰 간 지연은 다음과 같습니다.
핵심 쟁점: TTFT를 포함하느냐 마느냐
도구마다 계산 방식이 다릅니다.
GenAI-Perf 방식 — TTFT를 제외하여 순수 디코딩 성능만 측정합니다:
분모가 N-1인 이유는, 첫 번째 토큰은 Prefill의 결과물이지 디코딩 루프의 산출물이 아니기 때문입니다. N개의 토큰이 있으면 토큰 사이의 간격은 N-1개입니다.
LLMPerf 방식 — TTFT를 포함하여 평균을 냅니다:
같은 조건에서 LLMPerf 값이 더 크게 나옵니다. TTFT 비중이 클수록 차이가 벌어집니다.
예시: 출력 5토큰, latency = 500ms, TTFT = 100ms
이 경우 우연히 동일하지만, TTFT가 더 크거나 출력이 짧으면 값이 달라집니다.
출력 시퀀스가 길어질수록 KV-Cache가 커져서 ITL이 점점 나빠질 수 있습니다. ITL이 일정하게 유지된다면, 메모리 관리와 Attention 연산이 효율적이라는 의미입니다.
하지만 ITL 를 다루면서 유의할 점이 있습니다.
사용자는 평균 이라고 하는 것은 굉장히 거친 지표라는 것을 인지해야 합니다.
한 요청 안에서 토큰 100개가 생성됐는데, 99개는 50ms에 나오고 1개가 500ms 걸렸다고 하면
평균 ITL = (50×99 + 500×1) / 99 ≈ 54.5ms ← 괜찮아 보임
하지만 사용자는 스트리밍 중에 0.5초 동안 멈추는 걸 체감합니다. 평균으로는 이 스터터(stutter)가 완전히 묻힙니다.
단일 요청 안에서도 ITL이 일정하지 않은 원인이 여러 가지 있습니다:
- KV-Cache 증가: 출력이 길어질수록 매 스텝마다 읽는 메모리가 커져서 후반부 ITL이 점점 느려짐
- Prefill 간섭: continuous batching 환경에서 다른 요청의 Prefill이 끼어들면, 내 Decode가 밀려서 특정 토큰에서 갑자기 ITL이 튐
- 메모리 재할당: KV-Cache가 Paged Attention 블록 경계를 넘을 때 새 블록 할당이 발생
- GC/스케줄링 지터: GPU 스케줄러, Python GC 등 시스템 레벨 간섭
그래서 실무에서는 반드시 한 요청에서 토큰 수신 단위로 시간을 하나하나씩 전부 측정한 다음, ITL을 백분위수로 봐야 합니다.
위에서 보여지는 공식은 단순 평균 ITL 일 뿐입니다.
TPS (Tokens Per Second)
TPS는 관점에 따라 두 가지로 나뉩니다.
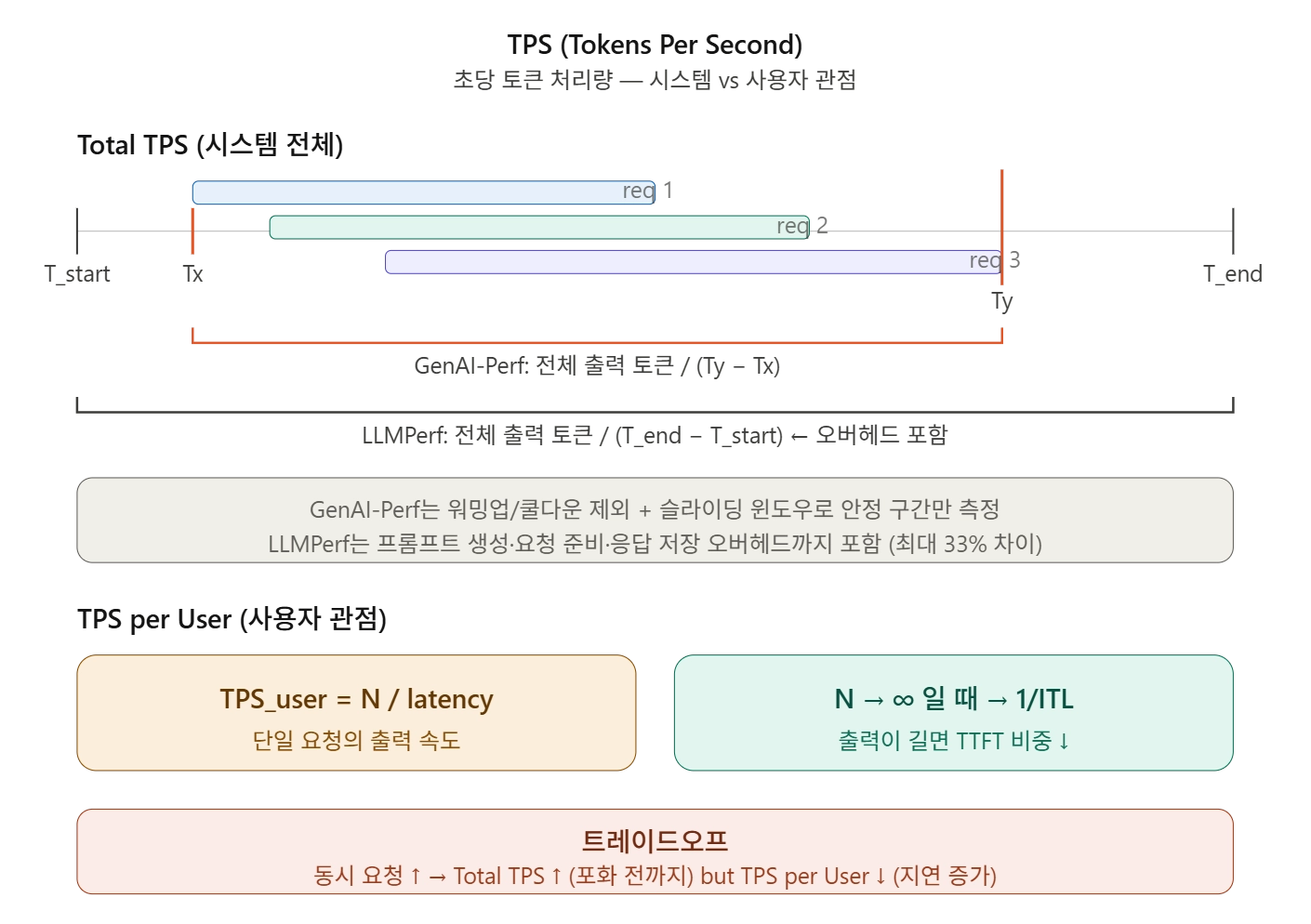
Total TPS (시스템 전체 처리량)
동시에 처리되는 모든 요청의 출력 토큰 총합을 시간으로 나눈 값입니다. 동시 요청(concurrency)이 늘면 Total TPS도 증가하지만, GPU 자원이 포화되면 감소로 전환됩니다.
벤치마크 타임라인의 기호를 먼저 정의합니다:
- T_start: 벤치마크 시작 시점
- Tx: 첫 번째 요청이 전송된 시점
- Ty: 마지막 요청의 마지막 응답이 수신된 시점
- T_end: 벤치마크 종료 시점
GenAI-Perf — 실제 추론 구간만 측정합니다:
LLMPerf — 벤치마크 전체 기간으로 나눕니다:
LLMPerf 방식에는 입력 프롬프트 생성, 요청 준비, 응답 저장 등의 오버헤드가 포함되어, 단일 동시성(concurrency=1) 시나리오에서 최대 33% 의 차이가 발생할 수 있습니다.
GenAI-Perf는 슬라이딩 윈도우 기법으로 안정 구간(stable measurement)만 추출하여 계산하며, 워밍업(warming up)과 쿨다운(cooling down) 기간의 요청은 제외합니다.
TPS per User (사용자 관점 처리량)
단일 사용자 한 명의 요청에 대한 처리량입니다
출력이 충분히 길어지면, TTFT의 비중이 줄어들면서 이 값은 1/ITL에 수렴합니다:
트레이드오프: 동시 요청이 늘면 시스템 전체 TPS는 올라가지만, 개별 사용자의 TPS는 지연 증가로 인해 떨어집니다.
TPSuser 의 한계는 명확합니다. 광범위하게 디코딩 시간이 포함되지 않을 수도 있는 latency 를 가지고 분모를 하다보니, 실제 디코딩 처리량과 TPSuser의 값이 훨씬 낮게 측정될 수 있습니다.
그럼 이 지표(TPS per User)는 왜쓰나?
TPS_user는 디코딩 성능 지표가 아닙니다. "사용자가 요청 보내고 응답 다 받기까지, 체감상 초당 몇 토큰을 받았나"라는 UX 관점 지표입니다. TTFT 동안 멍하니 기다린 시간도 사용자 경험의 일부니까 분모에 넣는 겁니다.
RPS (Requests Per Second)

시스템이 1초 동안 완료할 수 있는 평균 요청 수입니다.
TPS가 토큰 단위 처리량이라면, RPS는 요청 단위 처리량입니다. 둘의 관계는 다음과 같습니다:
여기서 N̄_output은 요청당 평균 출력 토큰 수입니다. 시스템 용량 계획에서 "동시 몇 명까지 감당할 수 있는가"를 산정하는 기준 지표입니다.
Cache Hit (KV-Cache 재사용률)
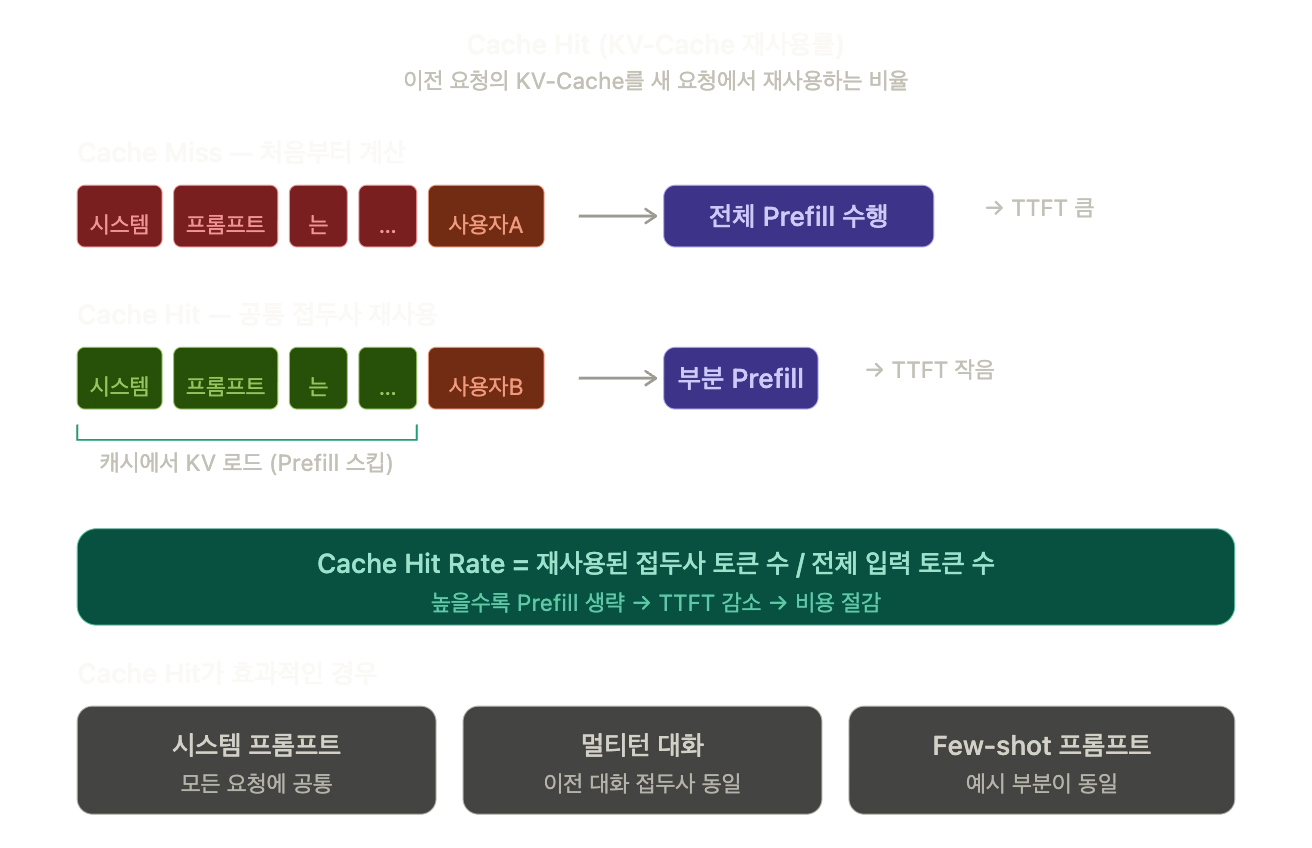
정의: 여러 요청이 동일한 접두사(시스템 프롬프트, 이전 대화 내역 등)를 공유할 때, 해당 부분의 KV-Cache를 다시 계산하지 않고 메모리에서 로드하는 비율입니다.
Cache Hit가 높으면 Prefill 대상 토큰 수가 줄어들어 TTFT가 크게 감소하고, GPU 연산도 절약됩니다.
Cache Hit가 효과적인 경우:
- 시스템 프롬프트: 모든 요청에 공통으로 붙는 긴 지시문
- 멀티턴 대화: 이전 대화 히스토리가 접두사로 동일
- Few-shot 프롬프트: 예시 부분이 고정
vLLM의 Automatic Prefix Caching이나 TensorRT-LLM의 KV-Cache Reuse가 이 기법의 대표적인 구현입니다.
메트릭 간 관계 요약
모든 메트릭은 서로 연결되어 있습니다:
GenAI-Perf vs LLMPerf
| 항목 | GenAI-Perf | LLMPerf |
|---|---|---|
| ITL 계산 | TTFT 제외, 분모 N−1 | TTFT 포함, 분모 N |
| TPS 계산 구간 | Ty − Tx (실제 추론 구간) | T_end − T_start (전체 벤치마크 구간) |
| 워밍업/쿨다운 제외 | ✅ (슬라이딩 윈도우) | ❌ |
| 빈 응답·done 시그널 | 제외 | 포함될 수 있음 |
동일한 메트릭 이름이라도 도구에 따라 계산 방식이 다르므로, 벤치마크 결과를 비교할 때는 반드시 어떤 도구로 측정했는지를 함께 명시해야 합니다.