[Python][중급] 웹 프레임워크의 시작, Flask — Werkzeug 위의 구조적 의견
들어가며
지금까지 우리는 아래에서 위로 올라왔다.
소켓에서 출발하여 WSGI 서버(Gunicorn)를 거쳐, WSGI 표준(environ + start_response)을 이해했고, Werkzeug가 이 표준을 Request/Response 객체로 감싸는 과정까지 살펴보았다.
그런데 Werkzeug만으로 애플리케이션을 작성하면, 여전히 개발자가 직접 결정해야 할 것이 많다. URL과 핸들러 함수를 어떻게 연결할 것인가? 요청 데이터를 핸들러에 어떻게 전달할 것인가? 여러 모듈로 나뉜 코드를 어떻게 하나의 앱으로 조합할 것인가?
프레임워크는 이런 질문들에 대해 미리 정해진 답을 제공한다. Flask는 Werkzeug의 도구 위에 "이렇게 하라"는 구조적 의견(opinions)을 더한 것이다. 이 글에서는 Flask가 정확히 무엇을 더하는지, 그리고 그것이 내부적으로 어떻게 동작하는지를 Werkzeug와의 관계를 중심으로 파고든다.
Flask = Werkzeug + 구조적 의견
Flask의 공식 설명은 "마이크로 웹 프레임워크"다. "마이크로"라는 표현은 기능이 적다는 뜻이 아니라, 코어가 작고 확장 가능하다는 뜻이다. 그 작은 코어가 정확히 무엇인지를 보자.
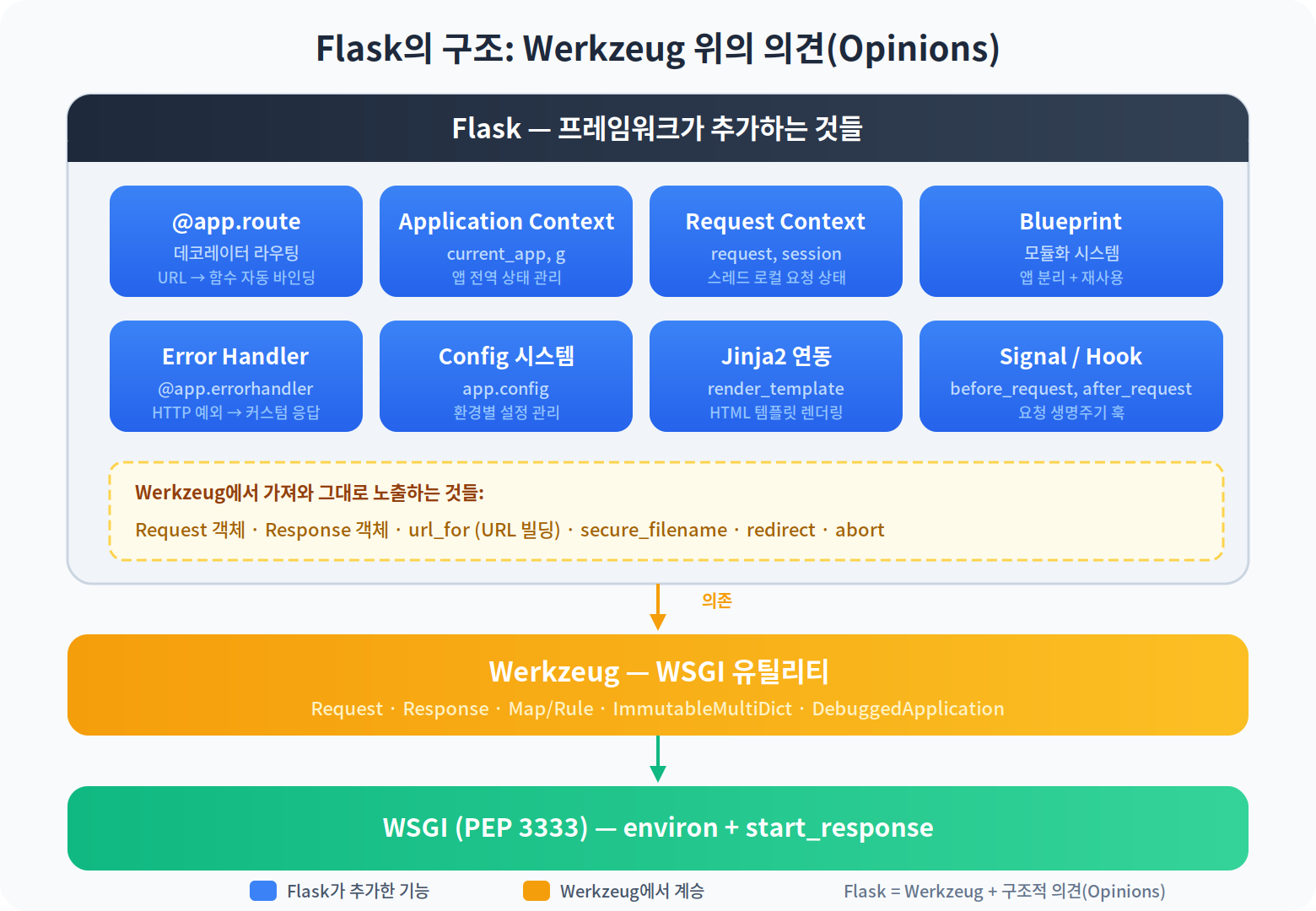
Werkzeug가 이미 제공하는 것들 — Request, Response, Map/Rule, redirect, abort, secure_filename 등 — 은 Flask가 그대로 가져와서 재노출한다. from flask import request의 request는 Werkzeug의 Request를 확장한 것이고, from flask import redirect는 Werkzeug의 redirect 그 자체다.
Flask가 새로 추가하는 것은 크게 네 가지다. 데코레이터 라우팅(@app.route), 컨텍스트 시스템(request, session, g, current_app), 생명주기 훅(before_request, after_request), 그리고 모듈화 시스템(Blueprint)이다.
이 네 가지를 하나씩 깊이 들여다보자.
데코레이터 라우팅: @app.route의 내부
Werkzeug의 라우팅을 기억하자
Werkzeug 글에서 우리는 Map과 Rule로 라우팅을 구현했다. URL 패턴을 엔드포인트 문자열에 매핑하고, 엔드포인트 문자열을 핸들러 함수에 연결하는 두 단계 구조였다.
# Werkzeug 방식 — 명시적이지만 번거롭다
from werkzeug.routing import Map, Rule
url_map = Map([
Rule('/', endpoint='index'),
Rule('/users/<int:user_id>', endpoint='user_detail'),
])
view_functions = {
'index': on_index,
'user_detail': on_user_detail,
}
Rule을 정의하고, view_functions 딕셔너리에 핸들러를 등록하는 것을 개발자가 직접 해야 한다. Flask의 @app.route는 이 두 단계를 하나의 데코레이터로 자동화한다.
@app.route가 하는 일
from flask import Flask
app = Flask(__name__)
@app.route('/users/<int:user_id>')
def user_detail(user_id):
return f'User #{user_id}'
이 데코레이터가 내부적으로 수행하는 작업을 풀어쓰면 다음과 같다.
# @app.route('/users/<int:user_id>')는 사실 이것과 같다
def user_detail(user_id):
return f'User #{user_id}'
# 1. Werkzeug Rule을 생성하여 url_map에 추가
app.url_map.add(Rule('/users/<int:user_id>', endpoint='user_detail'))
# 2. endpoint → 함수 매핑을 view_functions에 등록
app.view_functions['user_detail'] = user_detail
@app.route는 Werkzeug의 Map.add(Rule(...))과 view_functions[endpoint] = func를 한 번에 처리하는 편의 장치다. 내부를 들여다보면 Flask 앱 객체는 self.url_map(Werkzeug Map 인스턴스)과 self.view_functions(딕셔너리)를 갖고 있으며, @app.route가 양쪽에 동시에 등록하는 것이다.
엔드포인트의 의미
Flask에서 엔드포인트는 기본적으로 함수 이름이다. 명시하지 않으면 endpoint=함수.__name__이 된다.
@app.route('/')
def index(): # endpoint = 'index'
return 'Home'
@app.route('/about')
def about_page(): # endpoint = 'about_page'
return 'About'
이 엔드포인트는 url_for에서 사용된다. url_for('index')는 '/'를, url_for('about_page')는 '/about'을 반환한다. Werkzeug 글에서 다룬 역방향 URL 빌딩이 Flask에서는 이렇게 자동으로 연결된다.
HTTP 메서드 제어
@app.route('/login', methods=['GET', 'POST'])
def login():
if request.method == 'POST':
# 로그인 처리
return redirect(url_for('index'))
return render_template('login.html')
methods 파라미터는 Werkzeug Rule의 methods 인자로 전달된다. 허용되지 않은 메서드로 요청이 오면, Werkzeug가 자동으로 405 Method Not Allowed를 발생시킨다. 이 동작은 Flask가 아닌 Werkzeug 수준에서 처리되는 것이다.
컨텍스트 시스템: Flask의 가장 중요한 설계 결정
Flask의 컨텍스트 시스템은 프레임워크의 가장 핵심적인 — 그리고 가장 오해받기 쉬운 — 부분이다. from flask import request로 임포트한 request가 어떻게 매 요청마다 다른 데이터를 반환하는지, 그 메커니즘을 정확히 이해해보자.
문제: 전역 변수의 딜레마
Werkzeug에서는 Request 객체를 매 요청마다 직접 생성하여 핸들러에 인자로 전달했다.
# Werkzeug 방식 — request를 명시적으로 전달
def application(environ, start_response):
request = Request(environ) # 매 요청마다 생성
handler = get_handler(request)
response = handler(request) # 인자로 전달
return response(environ, start_response)
이 방식은 명확하지만, 핸들러가 다른 함수를 호출하고, 그 함수가 또 다른 함수를 호출하면 request를 계속 인자로 넘겨야 한다.
# request를 체인 전체에 전달해야 한다
def handler(request):
user = get_current_user(request)
permissions = check_permissions(request, user)
data = fetch_data(request, user, permissions)
return render(request, data)
Flask는 이 번거로움을 해결하기 위해 request를 전역처럼 보이는 프록시 객체로 만들었다.
# Flask 방식 — request를 어디서든 임포트
from flask import request
@app.route('/users')
def list_users():
page = request.args.get('page', 1)
return render_users(page)
def render_users(page):
# 여기서도 request에 접근 가능 — 인자로 받지 않아도 된다
if request.headers.get('Accept') == 'application/json':
return jsonify(users)
return render_template('users.html', users=users)
하지만 이게 진짜 전역 변수라면, 멀티 스레드 환경에서 문제가 된다. 스레드 A의 GET /users?page=2와 스레드 B의 POST /login이 동시에 처리될 때, request가 하나뿐이면 데이터가 섞인다.
So? → 컨텍스트 로컬 스택
Flask의 request는 전역 변수가 아니다. 현재 스레드(또는 그린렛)의 컨텍스트 스택 최상단을 가리키는 프록시 객체다.

내부 동작을 단순화하면 이렇다.
# Flask 내부의 개념적 구조 (실제 코드는 더 복잡하지만 원리는 같다)
import threading
# 스레드별로 독립적인 저장소
_request_ctx_stack = threading.local()
class RequestProxy:
"""request 프록시 — 현재 스레드의 컨텍스트에서 실제 Request를 가져온다"""
def __getattr__(self, name):
# 현재 스레드의 스택 최상단에서 Request를 꺼내서 속성에 접근
ctx = _request_ctx_stack.stack[-1]
return getattr(ctx.request, name)
# 이것이 from flask import request로 임포트되는 객체
request = RequestProxy()
핵심은 threading.local()이다. 이 객체는 스레드마다 독립적인 저장 공간을 제공한다. 스레드 A에서 _request_ctx_stack.stack에 접근하면 스레드 A의 스택이 나오고, 스레드 B에서 접근하면 스레드 B의 스택이 나온다. 따라서 request.args를 호출하면, 현재 스레드에 push된 RequestContext의 Request 객체에서 args를 가져오게 된다.
두 가지 컨텍스트
Flask는 두 개의 컨텍스트를 관리한다.
Application Context는 애플리케이션 수준의 정보를 담는다. current_app(현재 Flask 앱 인스턴스)과 g(요청 스코프 내의 임시 저장소)를 제공한다.
from flask import current_app, g
@app.route('/data')
def get_data():
# current_app — 현재 Flask 앱 인스턴스에 접근
db_url = current_app.config['DATABASE_URL']
# g — 이 요청 동안만 유효한 임시 저장소
if not hasattr(g, 'db'):
g.db = connect_to_database(db_url)
return query_data(g.db)
g 객체는 요청이 시작될 때 빈 상태로 생성되고, 요청이 끝나면 사라진다. 같은 요청 안에서 여러 함수가 데이터를 공유할 때 사용한다. DB 커넥션을 before_request에서 열고 teardown_request에서 닫는 패턴이 대표적이다.
Request Context는 개별 HTTP 요청의 정보를 담는다. request(Werkzeug Request 래퍼)와 session(쿠키 기반 세션)을 제공한다.
from flask import request, session
@app.route('/profile')
def profile():
# request — 현재 HTTP 요청 데이터
user_agent = request.headers.get('User-Agent')
# session — 쿠키 기반 세션 (요청 간 유지)
user_id = session.get('user_id')
if not user_id:
return redirect(url_for('login'))
return render_template('profile.html')
컨텍스트의 Push와 Pop
컨텍스트는 요청 처리의 시작과 끝에서 자동으로 push/pop된다.
# Flask 내부의 동작을 의사 코드로 표현
class Flask:
def wsgi_app(self, environ, start_response):
# 1. 컨텍스트 생성 및 Push
ctx = RequestContext(self, environ)
ctx.push()
# 이 시점부터 request, session, current_app, g가 유효하다
try:
# 2. 요청 처리
response = self.full_dispatch_request()
# 3. 응답 반환
return response(environ, start_response)
finally:
# 4. 컨텍스트 Pop — 반드시 실행된다
ctx.pop()
# 이 시점부터 request, session 등이 무효화된다
try/finally로 감싸져 있으므로, 예외가 발생해도 컨텍스트는 반드시 정리된다. 이것이 요청 간 상태 누수를 방지하는 메커니즘이다.
테스트에서의 컨텍스트
컨텍스트 시스템의 구조를 이해하면, 테스트 코드에서 왜 with app.test_request_context()가 필요한지 납득이 된다.
# 이 코드는 요청 컨텍스트 바깥이므로 실패한다
url = url_for('index') # RuntimeError: Working outside of request context
# 테스트에서는 수동으로 컨텍스트를 push해야 한다
with app.test_request_context('/'):
# 이 블록 안에서는 request, url_for 등이 유효하다
url = url_for('index') # '/'
# with 블록을 벗어나면 컨텍스트가 pop된다
test_request_context는 가짜 environ으로 RequestContext를 생성하여 push하는 것이다. WSGI 서버 없이도 Flask의 컨텍스트 의존 기능을 사용할 수 있게 해준다.
요청 처리 생명주기
@app.route와 컨텍스트를 이해했으니, 하나의 HTTP 요청이 Flask 내부를 관통하는 전체 흐름을 추적해보자.
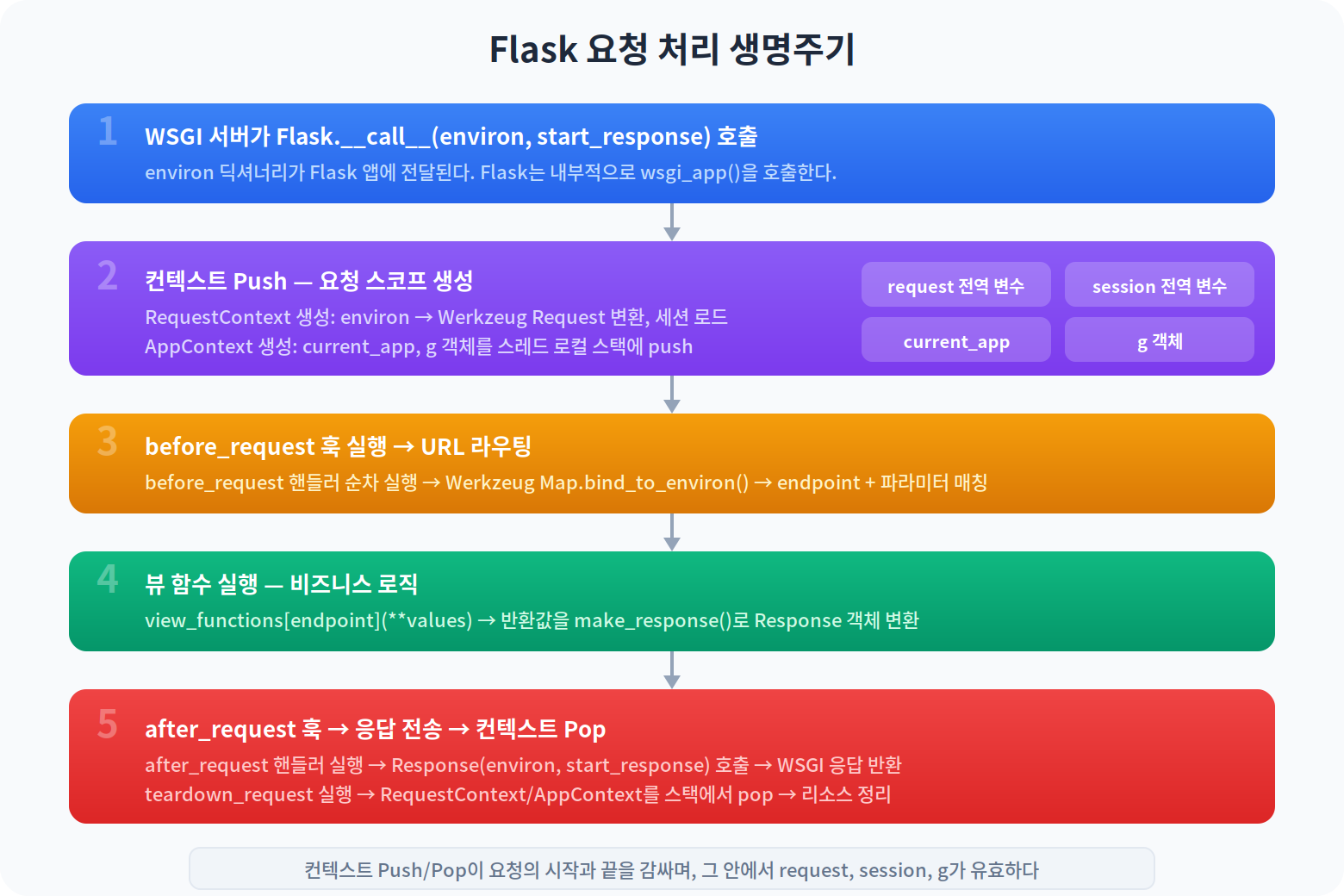
이 흐름을 코드와 함께 각 단계별로 풀어본다.
WSGI 진입
# Gunicorn이 이 메서드를 호출한다
app(environ, start_response)
# Flask.__call__은 wsgi_app을 호출한다
class Flask:
def __call__(self, environ, start_response):
return self.wsgi_app(environ, start_response)
__call__과 wsgi_app의 분리는 Werkzeug 글에서 다룬 패턴 그대로다. 미들웨어를 app.wsgi_app = Middleware(app.wsgi_app)처럼 끼워넣을 수 있다.
before_request 훅
@app.before_request
def check_auth():
"""모든 요청 전에 실행된다"""
if request.endpoint != 'login' and 'user_id' not in session:
return redirect(url_for('login'))
# None을 반환하면 정상 진행
# Response를 반환하면 뷰 함수를 건너뛰고 즉시 응답
@app.before_request
def connect_db():
g.db = get_db_connection()
before_request 핸들러는 등록된 순서대로 실행된다. 핸들러가 None이 아닌 값을 반환하면, 그것이 응답이 되고 뷰 함수는 실행되지 않는다. 인증 체크나 DB 연결 같은 공통 로직을 이 훅에 넣는다.
URL 매칭과 뷰 함수 실행
# Flask 내부의 디스패치 로직 (단순화)
def dispatch_request(self):
# Werkzeug의 url_map에서 현재 요청에 맞는 endpoint와 파라미터 추출
rule = request.url_rule
endpoint = rule.endpoint
values = request.view_args
# endpoint에 매핑된 뷰 함수 호출
return self.view_functions[endpoint](**values)
여기서 request.url_rule과 request.view_args는 컨텍스트 push 단계에서 이미 계산되어 있다. Werkzeug의 Map.bind_to_environ(environ).match()가 이 시점에 호출된다.
반환값의 Response 변환
Flask 뷰 함수는 다양한 타입을 반환할 수 있다. Flask가 이를 일관된 Response 객체로 변환한다.
@app.route('/text')
def return_text():
return 'Hello' # 문자열 → Response(body='Hello', status=200)
@app.route('/tuple')
def return_tuple():
return 'Created', 201 # 튜플 → Response(body='Created', status=201)
@app.route('/tuple-headers')
def return_with_headers():
return 'OK', 200, {'X-Custom': 'value'} # 헤더 포함 튜플
@app.route('/json')
def return_dict():
return {'key': 'value'} # 딕셔너리 → jsonify({'key': 'value'})
@app.route('/response')
def return_response():
resp = make_response('Custom')
resp.headers['X-Custom'] = 'value'
return resp # Response 객체 그대로 반환
이 변환은 make_response() 내부에서 일어난다. 문자열이면 Response로 감싸고, 딕셔너리면 jsonify를 거치며, 튜플이면 각 요소를 분해하여 Response를 구성한다. 개발자가 매번 Response 객체를 직접 생성하지 않아도 되게 해주는 편의 기능이다.
after_request와 teardown
@app.after_request
def add_security_headers(response):
"""모든 응답에 보안 헤더를 추가한다"""
response.headers['X-Content-Type-Options'] = 'nosniff'
response.headers['X-Frame-Options'] = 'DENY'
return response # 반드시 response를 반환해야 한다
@app.teardown_request
def close_db(exception):
"""요청 종료 시 DB 연결을 닫는다 — 예외 발생 여부와 무관"""
db = g.pop('db', None)
if db is not None:
db.close()
after_request는 정상 응답 시에만 실행되며, Response 객체를 받아 수정할 수 있다. teardown_request는 예외 발생 여부와 관계없이 항상 실행되며, 리소스 정리에 사용한다. teardown_request 이후 컨텍스트가 pop되면서 g, request, session이 모두 무효화된다.
Blueprint: 앱을 쪼개는 방법
애플리케이션이 커지면 하나의 파일에 모든 라우트를 넣을 수 없다. Flask의 Blueprint는 앱의 부분 집합을 정의하고 나중에 조합하는 메커니즘이다.
# blueprints/users.py
from flask import Blueprint, request, jsonify
users_bp = Blueprint('users', __name__, url_prefix='/api/users')
@users_bp.route('/')
def list_users():
return jsonify([...])
@users_bp.route('/<int:user_id>')
def get_user(user_id):
return jsonify({...})
@users_bp.before_request
def require_auth():
# 이 Blueprint의 라우트에만 적용되는 before_request
if not validate_token(request.headers.get('Authorization')):
return jsonify({'error': 'Unauthorized'}), 401
# app.py
from flask import Flask
from blueprints.users import users_bp
from blueprints.posts import posts_bp
app = Flask(__name__)
app.register_blueprint(users_bp) # /api/users/*
app.register_blueprint(posts_bp) # /api/posts/*
Blueprint를 register_blueprint로 등록하면, Blueprint에 정의된 Rule들이 앱의 url_map에 합쳐지고, view_functions에 핸들러가 등록된다. Blueprint는 독립 실행되지 않는다. 반드시 Flask 앱에 등록되어야 동작한다.
Blueprint의 핵심 가치는 두 가지다.
첫째, 코드를 기능 단위로 분리하여 유지보수성을 높인다.
둘째, before_request 같은 훅을 Blueprint 스코프로 한정할 수 있어, 특정 기능에만 적용되는 로직을 깔끔하게 관리한다.
Flask의 에러 처리 철학
HTTP 예외의 통일
Werkzeug는 HTTP 에러를 Python 예외로 표현한다(NotFound, MethodNotAllowed 등). Flask는 이 위에 에러 핸들러 등록 시스템을 더한다.
from flask import jsonify
from werkzeug.exceptions import NotFound, InternalServerError
@app.errorhandler(404)
def not_found(error):
return jsonify({'error': 'Resource not found', 'path': request.path}), 404
@app.errorhandler(500)
def server_error(error):
return jsonify({'error': 'Internal server error'}), 500
@app.errorhandler(ValueError)
def handle_value_error(error):
# HTTP 예외뿐 아니라 일반 Python 예외도 잡을 수 있다
return jsonify({'error': str(error)}), 400
abort(404)를 호출하면 Werkzeug의 NotFound 예외가 발생하고, Flask는 등록된 @app.errorhandler(404)를 찾아 실행한다. 이 체인은 Werkzeug의 HTTPException 위에 Flask의 핸들러 매핑이 올라간 구조다.
디버그 모드와 Werkzeug 디버거
if __name__ == '__main__':
app.run(debug=True)
debug=True로 실행하면 두 가지가 활성화된다. Werkzeug의 인터랙티브 디버거(예외 발생 시 브라우저에서 Python 셸 사용)와 자동 리로더(코드 변경 감지 후 서버 재시작)다. 이 두 기능은 모두 Werkzeug가 제공하는 것이며, Flask는 설정만 전달한다.
Werkzeug에서 Flask로의 진화 비교
같은 기능을 Werkzeug 직접 구현과 Flask 구현으로 비교하면, 프레임워크가 흡수하는 복잡성이 명확하게 보인다.
# ─── Werkzeug 직접 구현 ───
from werkzeug.wrappers import Request, Response
from werkzeug.routing import Map, Rule
from werkzeug.exceptions import HTTPException
import json
url_map = Map([
Rule('/', endpoint='index', methods=['GET']),
Rule('/api/greet', endpoint='greet', methods=['GET']),
])
def on_index(request):
return Response('Home', content_type='text/plain')
def on_greet(request):
name = request.args.get('name', 'World')
data = json.dumps({'message': f'Hello, {name}!'})
return Response(data, content_type='application/json')
view_functions = {'index': on_index, 'greet': on_greet}
def application(environ, start_response):
request = Request(environ)
adapter = url_map.bind_to_environ(environ)
try:
endpoint, values = adapter.match()
response = view_functions[endpoint](request, **values)
except HTTPException as e:
response = e.get_response(environ)
return response(environ, start_response)
# ─── Flask 구현 ───
from flask import Flask, request, jsonify
app = Flask(__name__)
@app.route('/')
def index():
return 'Home'
@app.route('/api/greet')
def greet():
name = request.args.get('name', 'World')
return jsonify(message=f'Hello, {name}!')
Werkzeug 버전에서 개발자가 직접 한 것들 — url_map 정의, view_functions 딕셔너리 관리, Request 객체 생성, adapter.match() 호출, HTTPException 캐치, Response 반환 — 을 Flask가 모두 내부로 흡수했다.
개발자가 작성하는 코드는 비즈니스 로직만 남는다. URL은 무엇이고, 어떤 데이터를 받아서, 무엇을 반환하는가. 나머지는 프레임워크의 의견(opinions)이 처리한다.
Flask가 하지 않는 것들
Flask를 이해하려면 Flask가 의도적으로 포함하지 않은 것을 아는 것도 중요하다.
Flask에는 ORM이 없다(SQLAlchemy를 별도로 연동한다). 폼 검증이 없다(WTForms를 확장으로 사용한다). 사용자 인증 시스템이 없다(Flask-Login 등을 사용한다). 관리자 패널이 없다(Flask-Admin을 사용한다). 마이그레이션 도구가 없다(Flask-Migrate를 사용한다).
이것이 "마이크로"의 의미다. 코어는 라우팅, 컨텍스트, 템플릿 연동, 에러 처리만 담당하고, 나머지는 확장(extension) 생태계에 맡긴다.
Django가 "배터리 포함(batteries included)" 철학으로 이 모든 것을 내장하는 것과 대조된다.
이 설계 철학의 장점은 유연성이다.
SQLAlchemy 대신 다른 ORM을 쓸 수 있고, 템플릿 엔진도 Jinja2가 기본이지만 교체할 수 있다. 단점은 프로젝트 초기 세팅에 결정할 것이 많다는 것이다.
Django는 "이것을 쓰라"고 정해주지만, Flask는 "알아서 골라라"고 한다.
마치며
Flask는 Werkzeug라는 정교한 WSGI 유틸리티 위에 네 가지 구조적 의견을 더한 것이다. 데코레이터 라우팅으로 URL-함수 매핑을 자동화하고, 컨텍스트 시스템으로 요청 데이터를 전역처럼 접근 가능하게 하며, 생명주기 훅으로 요청 전후의 공통 로직을 관리하고, Blueprint로 코드를 모듈화한다.
이 중 가장 중요한 것은 컨텍스트 시스템이다. from flask import request가 동작하는 원리 — 스레드 로컬 스택 위의 프록시 객체 — 를 이해하면, Flask의 거의 모든 동작이 자연스럽게 납득된다. 그리고 이 컨텍스트가 Werkzeug의 Request(environ)을 감싸고 있다는 것을 알면, 소켓에서 프레임워크까지의 전체 계층이 하나로 연결된다.
다음 글에서는 비동기 세계의 프레임워크인 FastAPI를 다루며, Flask의 동기 컨텍스트 모델이 비동기 환경에서 어떻게 변형되는지 비교할 것이다.