[LLM Serving] FasterTransformer: 거대 모델 추론을 위한 극한의 최적화
거대 언어 모델(LLM)을 실제 서비스에 적용하려고 할 때 가장 큰 장벽은 **속도(Latency)**와 **메모리(VRAM)**이다. PyTorch로 학습된 모델을 그대로 서빙하기에는 프로덕션 레벨의 성능을 내는 것이 불가능에 가깝다. 따라서 NVIDIA에서 공개한 고성능 추론 엔진인 **FasterTransformer(FT)**에 대해 깊이 있게 이해해보고자 한다.
1. Introduce
FasterTransformer(이하 FT)는 Transformer 계열의 모델을 위한 고성능 추론(Inference) 라이브러리이다. 주로 NVIDIA Triton Inference Server의 백엔드로 동작하며, 다음과 같은 특징을 가진다.
- Triton Server와의 결합: 상용 수준의 모델 서빙을 위해 Triton Server와 함께 사용
- C++/CUDA 기반 재작성: PyTorch나 TensorFlow와 같은 프레임워크 위에서 돌아가는 것이 아니라, 커널 레벨부터 C++와 CUDA로 다시 작성되어 극한의 속도 향상
- 범용성: Encoder-Only(BERT), Decoder-Only(GPT), Encoder-Decoder(T5) 등 대부분의 Transformer 아키텍처를 지원
사실 FT를 LLM Serving이라는 주제로 묶는 것은 정확한 표현이 아닐 수 있다. LLM을 프로덕션하기 위해서는
- LLM Model (PyTorch에서 제공)
- Execution Engine (Backend)
- Server (Backend에게 request를 전달)
세 가지 요소가 모두 필요하다.
최근 기술에서는 2번과 3번이 결합되어 LLM Serving Engine이 등장하는 추세이므로 2번의 기술만 갖고 있는 FT는 구식의 구조라고 말할 수 있다.
따라서 FT는 Triton Server와 결합되어 사용되는 단순 Backend Engine으로 보는 것이 더욱 정확하다.
(추후 Serving의 Layer에 대해 다루는 글 작성 예정)
내가 생각하는 FT의 가장 큰 의의는 단일 GPU로는 감당할 수 없는 모델을 Multiple GPU를 통해 실행하며, 여러 개의 GPU를 효율적으로 사용하는 것이다.
따라서 FT를 통해 LLM을 동작할 때, 어떻게 다중 GPU를 활용하는지 확인하며 아래 내용을 확인하면 도움이 될 것이다.
2. Architecture
FT는 **"The Transformer Block"**이라는 공용 블록을 기반으로 설계되어 있다.
이 블록 내에서 Self-Attention과 Feed-Forward Network가 실행되므로 다양한 형태의 모델을 유연하게 처리할 수 있는 것이다.
구조적으로는 크게 두 가지 핵심 요소로 구분할 수 있다.
2.1. Converter
- 역할: PyTorch/TensorFlow로 학습된 모델을 FT가 이해할 수 있는 바이너리 포맷으로 변환
- 최적화 수행: 단순히 파일 포맷만 바꾸는 것이 아니라, 변환 과정에서 **Weight Sharding(가중치 분할)**과 데이터 타입 변환(FP32 → FP16 등)과 같은 전처리 최적화를 수행
2.2. Backend
- 역할: 변환된 바이너리 파일을 메모리에 로드하고, 실제 클라이언트의 요청을 처리하는 서버 엔진
- 동작: Triton Server로부터 받은 명령을 수행하며, 사전에 정의된 C++/CUDA 커널을 통해 연산을 수행
3. Method: 병렬화 전략
단일 GPU로는 감당할 수 없는 거대 모델을 처리하기 위해 FT는 강력한 병렬화 기법을 제공한다.
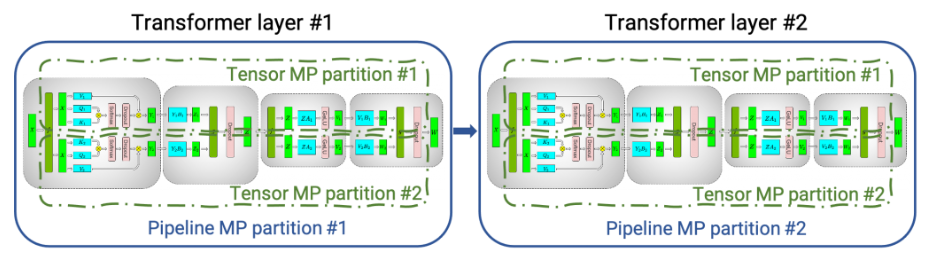
Tensor Parallelism - 상하로 쪼개진 초록색 점선 박스 2개: 하나의 행렬 곱(A X B)를 두 개의 GPU가 나눠서 실행(Megatron-LM의 방법 사용)
Pipeline Parallelism - 좌우로 쪼개진 파란색 실선 박스: Transformer의 Layer를 분리하여 좌우 각각의 GPU 2개씩 서로 다른 Layer를 처리, Micro-batch를 통해 다음 request를 처리하는 것도 가능
→ LLM 구동을 위해 총 4개의 GPU가 활용되고 있다.
3.1. Tensor Parallelism (TP)
- 개념: 하나의 거대한 행렬 곱 연산을 여러 GPU가 쪼개서 수행
- 장점: 각 GPU가 처리하는 연산량이 줄어들어 계산 속도(Latency) 비약적인 개선
3.2. Pipeline Parallelism (PP)
- 개념: 모델의 레이어(Layer)들을 그룹별로 나누어 서로 다른 GPU에 할당
- 장점: 각 GPU가 전체 모델의 Weight를 모두 가질 필요가 없으므로 메모리 부족(OOM) 문제를 해결
- 효율성: Micro-batch를 사용하여 유휴 시간(Bubble)을 줄이고 병렬 처리를 극대화
3.3. 데이터 전송 (Communication)
GPU 간의 협업(Sync)을 위해 MPI(Message Passing Interface)와 NCCL(NVIDIA Collective Communications Library)을 사용
- MPI: 통신 명령(Control)을 전달
- NCCL: 실제 데이터(Tensor)를 전송
- CPU-GPU 간 통신: PCIe 버스 사용
- GPU-GPU 간 통신: NVLink를 사용하여 대역폭(Bandwidth)을 극대화
즉, 명령하는 Manager와 실제로 옮기는 Worker가 분리되어 데이터 전송 효율 및 Sync를 최적화했다.
4. Optimizations in FT
FT Engine이 뛰어난 성능을 보일 수 있는 최적화 전략.
4.1. Layer Fusion (Kernel-level Optimization)
- 원리: MatMul, Bias Add, Activation 등의 자잘한 연산들을 하나의 커널로 해결
- 효과: 가장 느린 작업 중 하나인 Memory Access 횟수(Data transfer overhead)를 획기적으로 줄여 속도 증가.
4.2. Activations Caching (KV Cache)
- 원리: Autoregressive한 생성 과정(GPT 등)에서 이전 토큰의 Key, Value 연산 결과를 캐시에 저장
- 효과: 매 스텝마다 이전 토큰들을 다시 계산(Recomputation)할 필요가 없어 연산량 감소
4.3. Memory Optimization (Buffer Reuse)
- 원리: 각 Decoder Layer가 사용하는 Activation/Output 버퍼를 공유
- 예시: GPT-3가 96개의 Layer를 가진다면, 원래는 96개의 버퍼 공간이 필요하지만, FT는 이를 공유하여 1개의 버퍼 공간만 사용. 미리 메모리를 예약해둘 필요가 없음.
- 효과: 약 1/96로 메모리 사용량이 줄어들며, 절약된 메모리는 더 큰 Batch Size를 확보하는 데 사용 가능 (→ Throughput 증가)
4.4. Megatron-LM 방식의 Tensor Parallelism
- 첫 번째 행렬은 열(Column) 단위, 두 번째 행렬은 행(Row) 단위로 쪼개어 연산
- 이 방식을 사용하면 각 Transformer Block 내에서 Reduction(통신) 연산이 딱 2번만 발생하여 통신 오버헤드를 최소화
연산을 분리하여 Parallel하게 실행한다면 각 분리된 결과를 매번 일치시켜야 하는 Synchronization Overhead가 발생. 하지만 Megatron-LM의 방식을 통해서 모든 병렬이 각각 연산하고 가장 마지막에만 All-Reduce 하는 방법으로 연산 가능.
이는 Attention Block과 Feed-Forward Block에서 각각 한 번씩 발생하므로 총 2번만 발생.
4.5. GEMM Autotuning & Precision
- GEMM Autotuning: 런타임에 현재 하드웨어에서 가장 빠른 행렬 곱 알고리즘을 자동으로 찾아 적용
- Low Precision: FP32 대신 FP16, INT8을 사용하여 연산 속도를 높이고 VRAM을 절약합니다. Quantization 기술을 통해 정확도 손실을 최소화
추가적인 검증 시간/정확도 손실 이라는 trade-off가 발생하는 최적화 방법
하지만 trade-off를 감당하더라도 전체 LLM 성능을 높일 수 있기 때문에 최적화 기법으로 활용 가능.
5. Practice(Usage with Triton): 실제 활용 방법
앞서 언급했던 것처럼 FT는 Backend Library형태이므로 Triton Inference Sever와 결합하여 사용하는 것이 가장 안정적이다.
Step 1. Convert weights into FT format
PyTorch 체크포인트를 FT용 바이너리 및 설정 파일로 변환합니다. 이때 사용할 GPU 개수(-n-inference-gpus)에 맞춰 Weight Slicing이 일어납니다.
python3 ./FasterTransformer/examples/pytorch/gptj/utils/gptj_ckpt_convert.py \
--output-dir ./models/j6b_ckpt \
--ckpt-dir ./step_383500/ \
--n-inference-gpus 2
Step 2. Kernel-autotuning
하드웨어에 맞춰 최적의 GEMM 알고리즘을 탐색하여 설정 파일을 생성합니다.
./FasterTransformer/build/bin/gpt_gemm 8 1 32 12 128 6144 51200 1 2
Step 3. Configure Backend
Triton 설정 파일(config.pbtxt)에 변환된 모델 경로와 병렬화 설정을 입력합니다.
parameters {
key: "tensor_para_size"
value: { string_value: "2" }
}
parameters {
key: "model_checkpoint_path"
value: { string_value: "./models/j6b_ckpt/2-gpu/" }
}
Step 4. Run Triton Server
Triton 서버를 실행합니다. 정상적으로 실행되면 HTTP/GRPC 포트가 열리고 모델 상태가 READY로 표시됩니다.
CUDA_VISIBLE_DEVICES=0,1 /opt/tritonserver/bin/tritonserver --model-repository=./triton-model-store/gptj/ &
Step 5. Client Request (Python)
Python 클라이언트를 통해 서버에 추론 요청을 보냅니다.
import tritonclient.http as httpclient
# Initialize client
client = httpclient.InferenceServerClient("localhost:8000", concurrency=1)
# Prepare inputs & Send request
inputs = prepare_inputs([["Hello, Artificial Intelligence!"]])
result = client.infer("fastertransformer", inputs)
print(result.as_numpy("OUTPUT_0"))
6. Conclusion
FasterTransformer는 거대 모델 서빙 시 마주하는 3가지 핵심 문제를 다음과 같이 해결한다.
- 모델이 너무 커서 메모리에 안 올라감:
→ Parallelism (TP & PP): GPU를 여러 대 묶어 Megatron-LM 방식 등으로 효율적으로 분산.
- Memory-bound (데이터 전송이 느림):
→ Fusion & Reuse: Layer Fusion으로 커널 런칭 및 메모리 접근 횟수 감소, Buffer Reuse로 메모리 사용량 획기적 절감.
- PyTorch는 서비스용으로 느림:
→ Low-level Optimization: C++/CUDA 재작성 및 GEMM Autotuning을 통해 하드웨어 성능을 극한까지 끌어올림.
결론적으로, FasterTransformer는 단일 GPU의 한계를 넘어 하드웨어 리소스를 극한으로 활용함으로써, 거대 언어 모델의 **실시간 서비스(Real-time Serving)**를 가능하게 만드는 핵심 기술이다.
하지만 FT가 처음 상용화 된 것은 2022년으로 기술의 발전 속도로 미루어 본다면 매우 구식 기술이 되었다.
현재로는 NVIDIA에서도 TensorRT-LLM을 활용하고 있으며, 오픈소스로 FT를 기반으로 발전한 vLLM 기술이 등장했다.
하지만 FT에서 사용된 최적화 기법들이 여전히 현대 서빙 엔진의 근간이 되기 때문에 FT를 이해하는 것은 최신 엔진들이 “어떻게 내부에서 돌아가는지” 그 원리를 이해하는데 필수적인 요소이다.
참고자료
https://developer.nvidia.com/blog/increasing-inference-acceleration-of-kogpt-with-fastertransformer/