Roofline Model: 내 코드의 병목은 어디인가? (feat. A100, Transformer)
LLM Serving Model의 최적화를 위해서, Prefill Phase와 Decoding Phase의 커널 단위 성능 측정을 필요하다. 단순히 "느리다/빠르다"를 넘어, 도대체 "왜" 느린지, 그리고 "어디까지" 빨라질 수 있는지를 명확히 하기 위해서는 하드웨어의 물리적 한계를 시각화할 필요가 있다.
이때 가장 강력한 도구가 바로 Roofline Model이다.
해당 글에서는 Roofline Model의 개념을 정리하고, 실제 A100 GPU를 기준으로 하드웨어 스펙이 어떻게 그래프로 그려지는지, 그리고 내 프로그램의 위치(Dot)를 어떻게 해석해야 하는지 정리해본다.
1. Roofline Model이란?
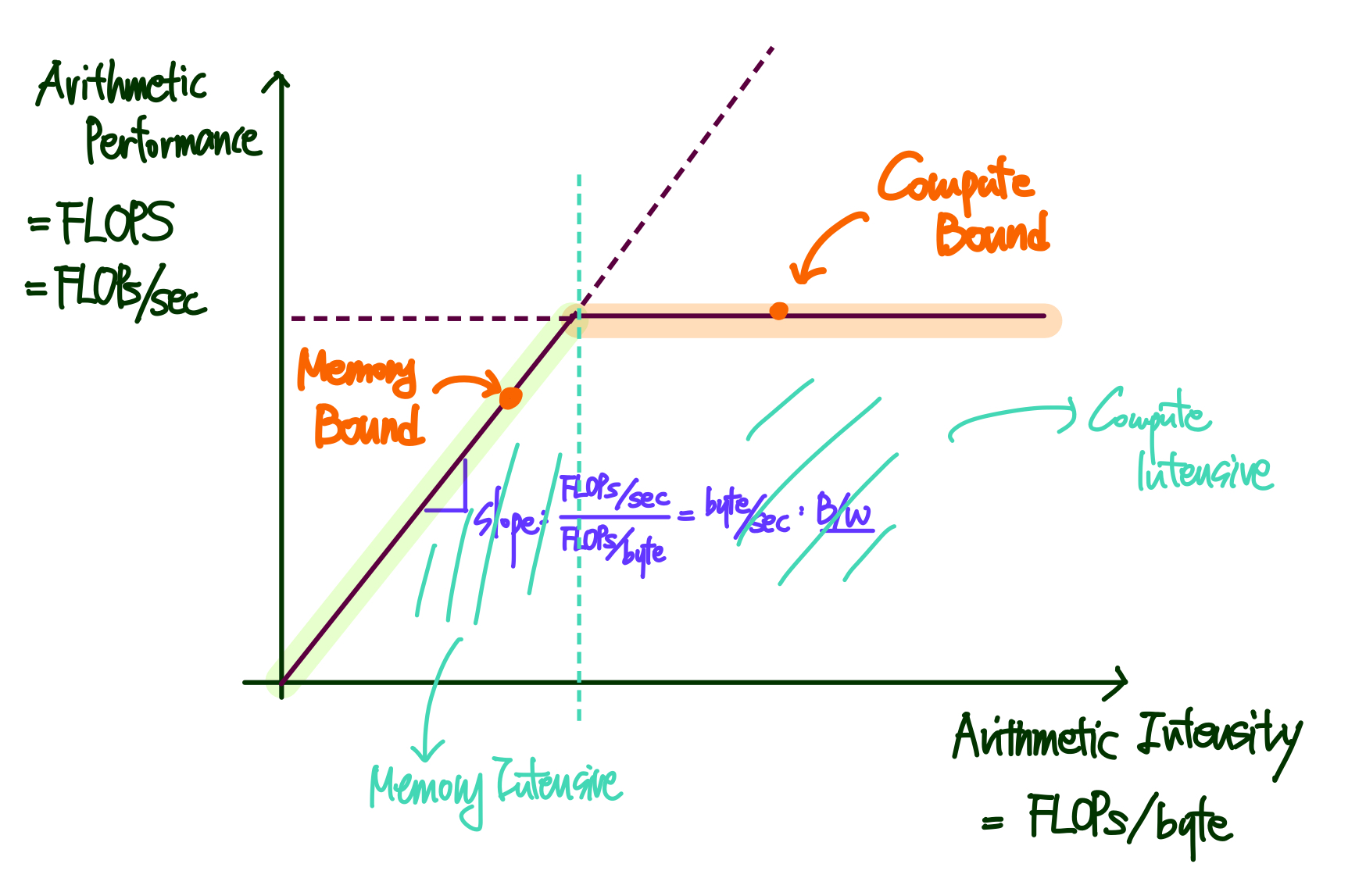
Roofline Model은 하드웨어의 성능 한계(Roof)와 소프트웨어의 실제 성능을 하나의 그래프에 표현하여 병목 구간을 시각적으로 파악하는 방법이다.
이 모델의 핵심은 "Roofline(지붕선)은 하드웨어 스펙에 의해 이미 결정되어 있다"는 점이다.
우리가 할 일은 이 정해진 지붕 아래에 내가 짠 커널의 성능 점(Dot)을 찍어보는 것이다.
두 개의 축 (Axes)
※ FLOP(Floating Point Operation) : 컴퓨터가 실수(Float) 데이터를 가지고 덧셈이나 곱셈을 1회 수행하는, 연산량의 가장 기초적인 단위
X축: Arithmetic Intensity (연산 강도)
◦ 단위:FLOPs/Byte
◦ 의미: 메모리에서 프로세서로 1 Byte의 데이터를 가져왔을 때, 해당 데이터로 몇 번의 연산(FLOP)을 수행하는가?
◦ 데이터의 재사용성을 나타낸다. 메모리에서 힘들게 가져온 데이터를 한 번 쓰고 버리는 것보다, 여러 번 활용하며(Cache hit) 연산을 많이 수행할수록 X축의 오른쪽(고강도)으로 이동.
◦ 이는 전적으로 **소프트웨어의 구조(알고리즘)**에 달렸다.Y축: Performance (성능)
◦ 단위:GFLOPSorTFLOPS(FLOPs/sec)
◦ 의미: 초당 실제로 처리하는 부동소수점 연산 횟수다.
2. 하드웨어로 그려지는 지붕 (The Roof)
Roofline은 크게 두 가지 형태의 직선으로 구성된다.
1) 기울어진 지붕 (Sloped Roof): Memory Bandwidth
그래프 앞부분의 사선 영역
이 기울기는 하드웨어의 메모리 대역폭(Bandwidth) 의해 결정
기울기의 단위를 살펴보면 그 이유가 명확해진다.
즉, 이 구간에서는 데이터를 메모리에서 얼마나 빨리 퍼 나를 수 있느냐가 성능의 상한선이 된다.

※ 메모리 대역폭(Bandwidth) : 프로세서와 메모리 간에 데이터를 전송할 수 있는 초당 최대 전송률
Bandwidth = (Memory Clock) × (Bus Width) × (Data Rate) × (Channel) / 8
Bus Width:
◦ 데이터가 이동하는 고속도로의 폭(차선 수). 물리적인 핀(Pin)의 개수와 직결되므로, 핀을 무한정 늘릴 수 없어 채널(Channel)을 늘리는 방식을 쓴다. (단위 보정을 위해 마지막에 8로 나눔: bit → byte)
Memory Clock:
◦ 데이터를 퍼 나르는 속도. 제조사 스펙이나 오버클럭 여부에 달렸다.
◦ 중요한 건 프로세서(CPU/GPU) 클럭과는 무관하다는 점이다.
Data Rate:
◦ 한 번의 클럭 신호에 데이터를 몇 번 보내는가? (DDR = Double Data Rate, 클럭당 2회 전송)
2) 평평한 지붕 (Flat Roof): Compute Peak
그래프 뒷부분의 평평한 영역
메모리 공급이 아무리 빨라도, 프로세서(연산기) 자체가 1초에 계산할 수 있는 물리적 한계에 도달한 상
Case Study: NVIDIA A100의 Roofline 계산
실제 연구에 사용할 A100 GPU를 기준으로 평평한 지붕의 높이(Max Performance)를 계산해보자.
- Streaming Multiprocessors (SM): 108개
- Tensor Cores per SM: 4개
- FMA (Fused Multiply-Add): 256회/cycle
- FLOPs per FMA: 2 FLOPs
- Clock Speed: 약 1.41 GHz

⚠️ 주의할 점:
위 계산은 FP16(반정밀도) Tensor Core를 사용했을 때의 기준이다. 만약 FP32로 연산한다면 A100의 성능은 19.5 TFLOPS로 급락한다.
Tensor Core는 애초에 FP16을 타겟하여 실행할 수 있는 HW → 최고의 성능이지만 최고의 정밀도는 아님
FP32를 사용한다면 Tensor Core는 포기해버리고 CUDA Core가 실행되는데, CUDA Core는 Tensor Core만큼 FLOP을 처리할 능력이 없기 때문에 성능이 급락하는 것.
즉, 사용하는 **데이터 정밀도(Precision)**에 따라 Roofline의 높이가 완전히 달라지므로, 그래프를 그릴 때 반드시 주의해야 한다.
3. 커널의 위치 확인 (Measurement)
하드웨어의 지붕을 그렸다면, 이제 실제 프로그램(원하는 대상 커널)을 돌려서 점을 찍을 차례다.
측정해야 할 지표는 딱 세 가지다.
Time: 실행 시간 (sec)
Data Movement: DRAM <-> Chip 간 이동한 데이터 양 (Byte)
FLOPs: 실제 수행된 부동소수점 연산 횟수
이 값들을 이용해 x = FLOPs/Byte, y = FLOPs/Time을 계산하여 그래프 위에 점을 찍는다.
4. 결과 해석 및 최적화 전략
점이 찍힌 위치에 따라 병목(Bottleneck)의 원인이 다르고, 최적화 방향도 달라진다.
Region A: Memory Bound (사선 영역 아래)
프로그램의 Arithmetic Intensity가 낮아서, 왼쪽의 사선 지붕 아래에 위치하는 경우
• 상태: 연산기는 놀고 있는데, 메모리에서 데이터가 늦게 도착해서 기다리는 상황.
• Sloped Roof에 닿은 경우: Memory Bound: 하드웨어의 메모리 대역폭을 100% 활용
소프트웨어만으로는 성능 향상이 불가능하며, HBM 같은 더 빠른 메모리가 필요하다. (혹은 알고리즘을 뜯어고쳐 Arithmetic Intensity 자체를 늘려야 한다.)
• Sloped Roof의 아래인 경우: Memory Intensive:
대역폭도 다 못 쓰고 있다. 메모리 접근 패턴이 비효율적이거나 캐시 미스가 심각한 상황
**메모리 접근 최적화(Coalesced Access 등)**를 통해 최적화 필요
Region B: Compute Bound (평평한 영역 아래)
프로그램의 Arithmetic Intensity가 높아서, 오른쪽 영역에 위치하는 경우
• 상태: 데이터는 충분히 빨리 공급되고 있으나, 연산기의 처리 속도가 한계에 다다른 상황.
• Flat Roof에 닿은 경우: Compute Bound:
하드웨어의 성능을 극한까지 활용
더 빠르게 하려면 더 좋은 GPU를 사거나, 연산 자체를 줄이는 경량화 알고리즘이 필요하다.
• Flat Roof의 아래인 경우: Compute Intensive:
연산 위주의 작업이지만, 명령어 파이프라인이 꼬이거나 병렬화가 제대로 안 된 상태
**ILP(Instruction Level Parallelism)나 벡터화(Vectorization)**를 통해 최적화 필요
5. 마치며
결국 Roofline Model은 최적화의 나침반이다.
Transformer의 Prefill Phase는 행렬곱 위주라 Compute Bound일 가능성이 높고,
Decoding Phase는 토큰 생성 특성상 Memory Bound일 가능성이 높다.
실제 측정을 통해 이 가설을 검증하고, 각 단계에 맞는 최적화 전략(PagedAttention의 최적의 파라미터를 적용)의 효과를 확인하는 것이 연구의 핵심이 될 것이다.
※ 참고 문헌
https://dl.acm.org/doi/10.1145/1498765.1498785