LLM 서빙 시스템을 최적화할 때, 대부분의 관심은 토큰을 생성하는 Decoding 단계에 집중된다.
그러나 실제 추론 파이프라인에는 Decoding 이전에 반드시 거쳐야 하는 단계가 있다. 입력 프롬프트 전체를 한꺼번에 처리하는 Prefill 단계다.
이 글에서는 점점 길어지는 입력 프롬프트 시대에, Prefill이 만들어내는 병목을 우아하게 해결하는 기법인 Chunked Prefill에 대해 다룬다.
Background: Prefill과 Decoding, 두 단계의 차이
LLM의 추론은 크게 두 단계로 나뉜다.
Prefill은 사용자가 입력한 프롬프트 전체를 모델에 한꺼번에 넣어 처리하는 단계다. 입력 토큰들이 이미 모두 주어져 있으므로, Transformer는 이를 병렬로 처리할 수 있다. 연산량은 많지만 GPU의 병렬 처리 능력을 최대한 활용하는 Compute-bound 작업이다.
Decoding은 그 이후 토큰을 하나씩 순차적으로 생성하는 단계다. 앞서 Speculative Decoding 글에서 다뤘듯, 이 단계는 매 step마다 모델 전체 파라미터를 메모리에서 읽어야 하는 Memory-bound 작업이다.
두 단계는 성격이 전혀 다른 연산이지만, 실제 서빙 시스템에서는 이 둘이 같은 GPU 자원을 두고 경쟁한다. 그리고 이 경쟁이 예상치 못한 병목을 만들어낸다.
Motivation: 긴 Prefill이 만드는 두 가지 문제
문제 1. 남는 Budget을 쓰지 못한다
LLM 서빙 시스템은 GPU 메모리나 연산 자원, 즉 Budget을 효율적으로 배분해야 한다.
기존 방식에서는 새로운 Request의 Prefill을 시작하려면 그 Prefill 전체를 처리할 수 있는 Budget이 한꺼번에 확보되어야 한다.
문제는 현재 Budget이 일부 남아 있어도, 그것이 Prefill 전체를 감당할 만큼 크지 않다면 해당 Request는 Queue에서 계속 기다려야 한다는 것이다.
남는 자원을 활용하지 못한 채 GPU가 놀고 있는 셈이다.
문제 2. 긴 Prefill이 Decoding을 멈춰 세운다 (핵심)
더 심각한 문제는 서비스 품질과 직결된다.
vLLM의 Iteration-level Scheduling처럼 정교한 스케줄링을 적용하더라도, 하나의 Iteration 안에 매우 긴 Prefill이 포함되면 그 Iteration 자체가 지나치게 길어진다.
해당 Iteration이 끝나야 다음 작업을 시작할 수 있으므로, 그동안 다른 Request들의 Decoding은 완전히 멈추게 된다.
사용자 입장에서는 스트리밍으로 응답을 받다가 갑자기 출력이 뚝 끊기는 현상으로 느껴진다.
내 요청도 아닌 다른 누군가의 긴 프롬프트 때문에, 내 화면의 텍스트 생성이 멈춰버리는 것이다.
핵심 아이디어: Prefill을 잘라서 나눠 처리한다
Chunked Prefill의 아이디어는 단순하다.
"Prefill 전체를 한 번에 처리하지 말고, 일정한 Budget 단위(Chunk)로 잘라서 여러 Iteration에 걸쳐 나눠 처리하자."
이것이 가능한 이유는 Prefill의 특성에 있다. Prefill은 Auto-regressive 생성 단계에 진입하기 전, 이미 알고 있는 입력 데이터에 대한 연산이다. 처음부터 끝까지 순서가 정해진 연산이기 때문에, 중간에 끊어서 실행해도 각 Chunk의 연산 결과는 동일하게 보장된다.
아래 그림이 이 차이를 잘 보여준다.
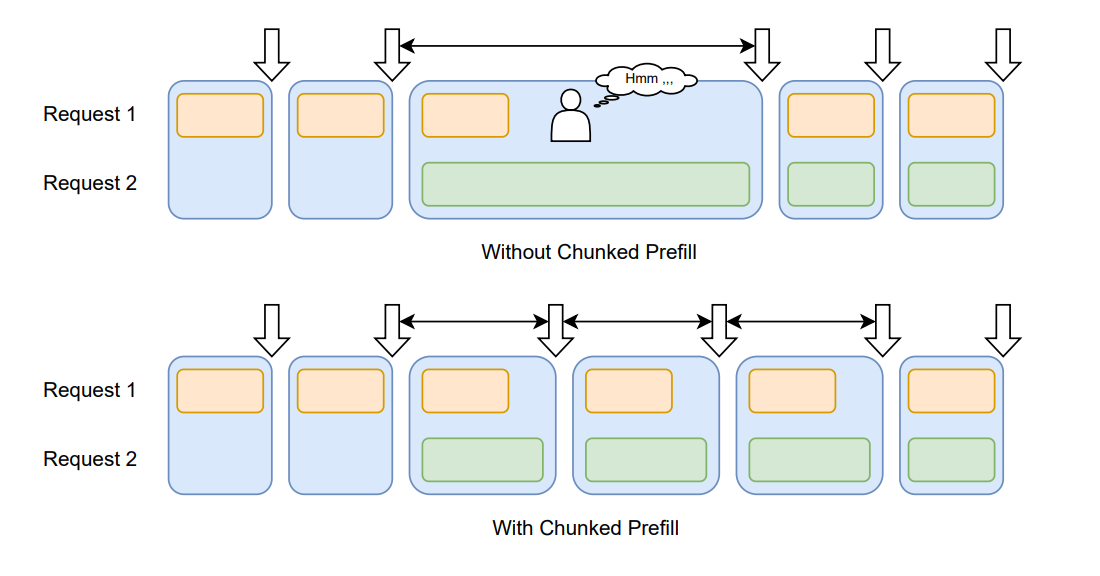
위: Chunked Prefill 미적용 시, 긴 Prefill(Request 2)이 하나의 Iteration을 통째로 점유하여 Request 1의 Decoding이 대기하는 상황.
아래: Chunked Prefill 적용 시, Prefill을 쪼개서 Decoding과 번갈아 처리하며 두 Request가 고르게 진행되는 상황.
위쪽 그림에서 가운데 큰 Iteration을 보면, Request 2의 Prefill이 그 Iteration을 통째로 차지하고 있다. Request 1의 Decoding은 이 Iteration이 끝날 때까지 아무것도 하지 못한다.
아래쪽 그림에서는 Prefill이 작은 Chunk들로 쪼개져, Decoding 작업과 번갈아가며 처리되고 있다. 각 Iteration이 짧고 균일해지면서, Request 1도 멈추지 않고 토큰을 계속 생성할 수 있다.
두 가지 효과
효과 1. GPU 활용률 향상
Chunking 덕분에 Budget이 일부만 남아 있어도 그 공간에 Prefill Chunk를 채워 넣을 수 있다.
기존에는 낭비되던 자투리 자원을 활용하게 되어 **GPU 활용률(Utilization)**이 높아진다.
다만 이 효과는 Budget이 애매하게 남는 특수한 상황에서 발생하는 것이므로, 전체적인 전체 성능 향상으로 이어지기보다는 안정적인 자원 활용에 기여한다고 보는 것이 적절하다.
효과 2. Decoding 지연 방지와 사용자 경험 개선
본질적인 효과는 여기에 있다.
Prefill을 Chunk 단위로 분산시킴으로써, 어떤 Iteration도 Prefill 때문에 지나치게 길어지지 않는다.
그 결과 Decoding Request는 Prefill이 길더라도 매 Iteration마다 꾸준히 처리될 수 있고, 사용자는 토큰이 끊기지 않고 계속 흘러나오는 경험을 하게 된다.
이것은 단순한 처리량(Throughput) 개선이 아니라, 사용자가 직접 체감하는 응답 품질의 개선이다.
이는 LLM Serving에서 중요하게 측정되는 ITL, 즉 Inter-Token-Laytency에 큰 영향을 주며, 특히 가장 긴 데이터를 모은 P99 ITL을 엄청나게 개선할 수 있다.
따라서 Chunked Prefill을 통해서 더 높은 QPS(Query per Second)를 감당하여 서빙 성능을 끌어올릴 수 있는 것이다.
Trade-Off: TTFT를 희생한다
Chunked Prefill이 ITL과 P99 ITL을 극적으로 개선하는 것은 사실이지만, 이 개선이 완전히 공짜는 아니다.
Prefill을 잘게 쪼개서 여러 Iteration에 분산한다는 것은, 역으로 Prefill 전체가 완료되기까지 더 많은 Iteration이 소요된다는 뜻이기도 하다.
Prefill이 완료되어야 첫 번째 출력 토큰이 생성될 수 있으므로, 결국 사용자가 첫 번째 토큰을 받기까지 걸리는 시간, 즉 TTFT(Time To First Token)가 늘어난다.
기존 방식에서는 Prefill을 한 번에 몰아서 처리하기 때문에, 해당 Request 입장에서는 가능한 한 빨리 Prefill을 끝내고 Decoding으로 넘어갈 수 있었다. Chunked Prefill은 이 흐름을 의도적으로 늦추는 대신, 다른 Request들이 그 사이에 Decoding을 진행할 수 있도록 양보하는 구조다.
정리하면 이렇다.
TTFT(첫 토큰 대기 시간)를 소폭 희생하는 대신, ITL(토큰 간 지연)을 크게 줄인다.
어떤 지표를 더 중요하게 볼 것인가는 서비스의 성격에 따라 다르다. 짧은 질의응답처럼 첫 응답 속도가 중요한 서비스라면 TTFT 증가가 민감하게 작용할 수 있다. 반면 긴 문서 생성이나 코드 작성처럼 스트리밍 품질이 중요한 서비스라면 ITL 개선의 효과가 훨씬 크게 체감된다.
결국 Chunked Prefill은 시스템 전체의 공정성(Fairness)을 높이는 기법이다. 특정 Request의 긴 Prefill이 다른 모든 Request의 Decoding을 인질로 잡는 상황을 막고, 자원을 고르게 나누는 방향으로 스케줄링을 재설계한 것이다.
Conclusion: Long Context 시대의 선제적 대응
Chunked Prefill은 구조 자체가 단순하다. 나누어서 처리한다는 것이 전부다.
그러나 이 단순한 아이디어가 해결하는 문제는 점점 더 중요해지고 있다.
입력 프롬프트가 수만 토큰에 달하는 Long Context 처리가 LLM의 핵심 요구사항이 되어가고 있기 때문이다.
긴 Prefill이 만들어내는 병목은 앞으로 더 자주, 더 심각하게 발생할 것이다.
FlashAttention이 Attention 연산의 IO 병목을 사전에 설계 단계에서 해결했듯,
Chunked Prefill은 서빙 스케줄링 레벨에서 Long Context가 만드는 불균형을 선제적으로 흡수한다.
하드웨어가 아닌 알고리즘과 스케줄링의 설계로 시스템의 한계를 밀어낸다는 점에서, 이 시리즈에서 다뤄온 최적화들과 같은 철학 위에 서 있다.