Transformer: Attention부터 Modern LLM의 추론 구조까지
인공지능 역사에 한 획을 그은 논문이 있다면 단연 구글의 2017년 논문 **"Attention Is All You Need"**일 것이다.
오늘날 우리가 사용하는 GPT, Llama, Claude 등 모든 LLM의 근간이 해당 논문에서 제안한 Transformer 아키텍처를 기반하고 있기 때문이다.
이번 글에서는 Transformer가 등장하게 된 배경부터 핵심 매커니즘인 Attention의 수학적 연산 과정, 그리고 최신 LLM이 채택하고 있는 최적화 기법(GQA, SwiGLU)과 추론 프로세스(Prefill/Decode)까지 깊이 있게 소개해 보겠다.
**1. Introduction: RNN의 한계와 Attention의 등장**
Transformer 이전, 자연어 처리(NLP)은 RNN(Recurrent Neural Network)과 LSTM을 중심으로 구성되었다. 하지만 더 나은 성능을 추구하다 보니 이것들은 구조적인 한계점을 드러냈다.
순차적 처리(Sequential Processing):
이전 hidden state()가 계산되어야만 현재()를 계산할 수 있다.
즉 반드시 순차적인 연산을 실행해야 하기 때문에, GPU의 강력한 병렬 처리 능력을 활용하지 못하여 성능 발전에 브레이크가 걸렸다.
Long-Term Dependency:
문장이 길어질수록 초반의 정보가 희석되는 문제가 발생한다.
사실 해당 구조 위에서 이미 Attention 메커니즘이 이를 보완하기 위해 도입되었으나, 여전히 RNN 위에 얹혀진 보조적인 역할에 불과했다.
"Attention Is All You Need"는 제목 그대로, "**RNN(Recurrence)과 CNN(Convolution)을 다 버리고, 오직 Attention만으로 모델을 만들어보자"**는 파격적인 제안을 한 논문이다. 이를 통해 완벽한 병렬 처리와 Global Dependency(문장 전체를 한 번에 참조)를 달성할 수 있게 되었다.
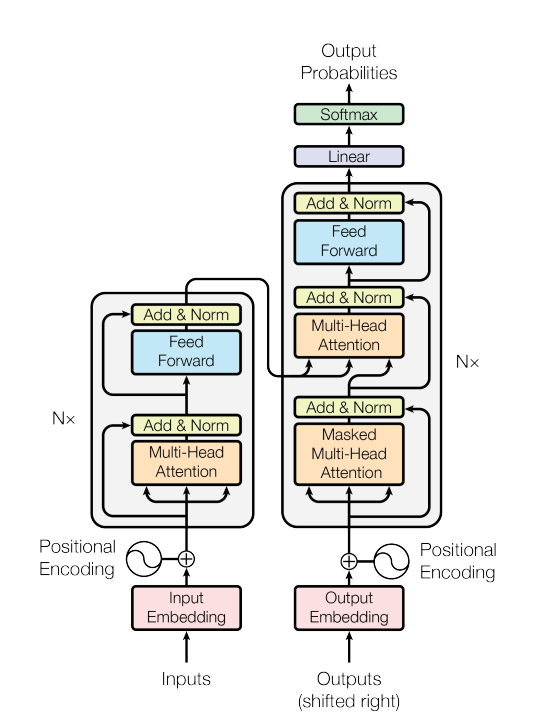
2. Architecture Deep Dive: Encoder & Decoder의 내부 데이터 흐름
Transformer 모델은 크게 좌측의 Encoder와 우측의 Decoder로 나뉩니다. 이들이 내부적으로 데이터를 어떻게 처리하는지, Input부터 Output까지의 파이프라인을 단계별로 뜯어보겠습니다.
Encoder (좌측):
입력 문장(Source)을 받아 문맥을 이해하고 압축된 벡터 표현(Context Vector)으로 변환하여 컴퓨터가 이해할 수 있도록 전처리 (예: 영어 문장 이해)
Decoder (우측):
인코더의 정보를 바탕으로 **정답 문장(Target)**을 순차적으로 생성 (예: 한글 문장 생성)
**2.1 Input Pipeline: Token ID to Vector**
컴퓨터는 '사과'라는 글자를 이해할 수 없다. 따라서 텍스트는 먼저 Tokenizer(모델에 정의되어 있는 부분)를 통해 정수 형태의 Token ID로 변환되어 모델에 입력된다.
Input Shape:
[Batch_Size, Sequence_Length](예:[1, 10]→ 10개의 단어로 구성된 1개의 문장이 요청으로 들어왔고, 그것을 Tokenizer가 10개의 Token ID로 변환해놓은 상태)※ Batch_Size: 들어오는 Request들을 한 번에 묶어서 모델에 연산을 요청하는 것을 “Batching한다”고 표현한다. 이것은 모델에게 요청을 Request를 보내는 ‘System’이 하는 역할이기 때문에 해당 글에서는 자세히 다루지 않고 1로 고정하도록 하겠다.(즉 단일 요청에 대해서 모델이 어떻게 처리하는지에 대해서만 관찰하겠다는 뜻이다.) 이에 대해서는 Serving System에 대해 다루는 vLLM, Orca, SGLang에 관련된 글을 참고하길 바란다.
Embedding Layer: 각 Token ID는 거대한 Lookup Table(Embedding Matrix)(모델에서 정의한 모델의 특성; “AI 모델을 연구한다”는 주제에서 이 Matrix를 어떻게 구성할지에 대해 고민하는 것)을 통과하며 고정된 크기의 실수 벡터()로 변환
Positional Encoding: Transformer는 순차적 정보(Recurrence)가 없기 때문에, 단어의 위치 정보를 담은 벡터(Positional Encoding)를 임베딩 벡터에 추가
- 각 단어들 사이의 관계를 표현하는 Attention만 데이터로 가지고 있기 때문에 서로 어느 위치에 있는지 알 수 없기 때문에, 미리 각 Token에다가 위치 정보를 추가해 두는 것이다.
Result Shape:
[Batch_Size, Sequence_Length, Hidden_Dim](예:[1, 10, 512])- 1개의 요청이 들어왔는데, 총 10개의 단어가 있는 것이고, 각 단어가 512개의 숫자로 표현된 상태
이제부터 모델 내부의 모든 데이터는 이 3차원 텐서 형태(벡터의 시퀀스)로 진행된다.
**2.2 The Stack (Nx): 모델의 깊이(Depth)**
다이어그램의 Nx 표시는 이 블록들이 N번 반복해서 쌓인다는 뜻이다. 모델에 대해서 언급할 때 흔히 말하는 "Hidden Layer가 많다" 혹은 "모델이 깊다(Deep)"는 것은 이 **Encoder/Decoder 블록의 개수()**가 많다는 것을 의미한다.
input → (Encoder → Decoder) → (Encoder → Decoder) → … → (Encoder → Decoder) → output
논문의 Base 모델은 이지만, 최신 LLM(Llama-3-70B 등)은 이 블록을 80개까지 사용한다. 데이터는 아래층에서 위층으로 순차적으로 통과하며 점점 더 추상적인 정보를 학습한다.
여기서 중요한 의문이 생긴다.
"똑같은 구조의 블록을 계속 쌓으면, 똑같은 연산을 반복하는 것 아닌가? 왜 굳이 깊게 만드는가?"
이 질문에 대한 답은 **"독립적인 파라미터"**와 **"계층적 학습(Hierarchical Learning)"**에 있다.
- 구조는 같지만, 내용은 다르다 (Independent Parameters)
모든 레이어는 이라는 동일한 수학적 구조를 가지고 있다. 하지만 그 안을 채우고 있는 가중치 행렬(Weight Matrices, **등)**의 값은 레이어마다 전부 제각각이며, 서로 독립적으로 학습된다.
해당 가중치 행렬이 흔히 말하는 “모델 파라미터”이며, 따라서 모델의 깊이가 깊어질수록 모델 파라미터가 더 큰, 더 무거운 모델이 되는 것이다.
비유하자면, 똑같은 책상과 컴퓨터(구조)를 사용하는 80명의 직원(레이어)이 일렬로 앉아 있지만, 각자 맡은 전문 분야와 지식(가중치)은 서로 다른 것과 같다.
※ 논문에서도 FFN(Feed-Forward Network)을 설명하며 **"레이어마다 서로 다른 파라미터를 사용한다"**고 명시하고 있다.
- 정보의 추상화 (Abstraction Pipeline)
데이터가 아래층(Layer 1)에서 위층(Layer N)으로 올라갈수록 처리하는 정보의 수준이 달라진다. 이를 딥러닝에서는 **표현 학습(Representation Learning)**의 깊이라고 부른다.
- Lower Layers (하위 계층): 주로 문장의 형태적, 문법적 특징에 집중한다. 인접한 단어끼리의 관계나 단순한 구문 구조를 파악한다.
- Middle Layers (중위 계층): 문맥을 파악하고 단어의 의미적 중의성을 해소한다. (예: '배'가 먹는 배인지 타는 배인지 구분)
- Higher Layers (상위 계층): 문장 전체의 논리적 흐름, 인과 관계, 혹은 매우 추상적인 개념을 다룬다.
- 비선형성의 축적 (Accumulation of Non-linearity)
각 레이어에는 **ReLU(혹은 GELU)**와 같은 활성화 함수가 포함되어 있다.
레이어를 깊게 쌓는다는 것은 이 비선형 변환을 수십 번 합성한다는 뜻입니다.
수학적으로, 얕은 모델은 복잡한 문제(고차원 데이터의 경계)를 분류하는 데 한계가 있다. 모델이 깊어질수록(Deep) 비선형성이 축적되어, 인간의 언어처럼 매우 복잡하고 미묘한 패턴을 수학적으로 근사(Approximation)할 수 있는 **표현력(Capacity)**이 기하급수적으로 증가한다.
즉, 입력된 텍스트는 수십 개의 레이어를 거치며 단순한 '단어의 나열'에서 '의미와 논리'를 담은 고차원 벡터로 **정제(Refinement)**되는 것이다.
**2.3 Encoder Block 내부 구조 (Left Side)**
Encoder의 각 레이어는 두 개의 Sub-layer로 구성된다.
- Multi-Head Attention (MHA): “여러 관점에서 동시에 본다.”
입력된 문장 내의 단어들끼리의 관계를 파악(Self-Attention).
보통의 표현으로 **“Attention Layer”**를 표현하는 단계
그런데 왜 하필 'Multi-Head'일까?
같은 문장을 읽어도 문법을 보는 관점, 의미를 보는 관점, 대명사가 무엇을 지칭하는지 찾는 관점이 다를 수 있다.
비유: 마치 8명의 전문가가 한 문장을 동시에 분석
- Head 1: "주어와 동사의 수 일치를 확인해." (문법)
- Head 2: "'그것(it)'이 앞 문장의 '사과'를 가리키고 있어." (지칭)
- Head 3: "문장 전체 분위기가 부정적이야." (감정)
이렇게 여러 헤드(Head)가 각자의 **독자적인 가중치()**를 가지고 입력 문장을 다양한 각도에서 병렬로 분석한 뒤, 나중에 합치는(Concat) 방식.
이것을 구현하는 방법은 개별 Token을 벡터로 바꾼 차원 데이터를, 각 Head가 차지하는 부분을 분할하여 담당을 지정하는 것이다.
예를 들어 각 Token Vector의 크기가 512 사이즈이고 8개의 Head를 가진 모델이라면,
Head 1: 64개의 데이터로 문법을 해석
Head 2: 64개의 데이터로 지칭을 해석
…
이렇게 담당을 나누어 분석하게 되는 것이다.
마지막에는 모든 Head를 다시 512차원을 Concat한다.
- Add & Norm:
- Add (Residual Connection):
SubLayer(x) + x형태
출력값을 다음 Layer로 바로 전달하는 것이 아니라, 입력값을 출력값에 더한 후 다음 단계로 전다하는 것이다.
이는 역전파 시 기울기 소실(Gradient Vanishing)을 막아 깊은 신경망 학습을 가능하게 하는 핵심 트릭이다.
- Norm (Layer Normalization): 데이터의 분포를 정규화하여 학습 속도와 안정성을 높인다.
- Feed Forward (FFN):
Attention Layer에서 단어 간의 관계를 본다면, FFN은 각 단어 벡터를 개별적으로 처리하여 정보를 확장하고 비선형성을 추가한다.
보통의 표현으로 “MLP”를 표현하는 단계
**2.4 Decoder Block 내부 구조 (Right Side)**
Decoder는 Encoder와 유사하지만 몇 가지 중요한 차이점이 있다.
- Masked Multi-Head Attention:
Decoder는 정답 Token을 생성하는 곳이다.
학습 시, 현재 위치()보다 미래의 단어()를 미리 보고 컨닝(Cheating)하는 것을 막기 위해, 미래 시점의 Attention Score를 -infinity로 마스킹(Masking)하여 접근을 차단한다.
→ 처음 input에서 여러 단어가 한 번에 들어온다면 분명 모델에 다음 단어가 존재하고 있지만, 각 단어를 순차적으로 확인해야 하기 때문에 뒷 부분을 Masking 하는 것이다.
- Encoder-Decoder Attention (Cross Attention):
Decoder 블록 중간에 있는 Attention 층
- Query (Q): Decoder의 현재 상태 (무엇을 번역/생성해야 하는가?)
- Key (K) / Value (V): Encoder의 출력값 (원본 문장의 문맥 정보)
이 과정을 통해 Decoder는 번역할 때 원본 문장의 어느 부분을 참고해야 할지 결정합니다.
**2.5 Output Head: Linear & Softmax**
Decoder의 최상단 레이어를 통과한 벡터는 여전히 [Batch, Seq, Hidden_Dim] 형태입니다. 이를 우리가 아는 **'단어'**로 바꾸기 위해 마지막 단계가 필요하다.
- Linear (Projection):
Hidden Dimension(예: 512) 크기의 벡터를 전체 단어장 크기(Vocabulary Size)(예: 30,000개)로 확장한다.
이때 나오는 값을 Logits라고 하며, 각 단어가 정답일 '점수'를 의미한다.
모델이 가지고 있는 모든 단어들에 대해서 다음 단어로 선택될 점수를 측정한 것이다.
- Softmax:
Logits 점수들의 값 범위가 Sequence에 따라 달라지기 때문에 각 Token들의 중요도를 파악하기 어렵다. 따라서 Softmax함수를 통화시켜 모든 점수를 0~1 사이의 확률값(Probability)으로 변환한다.
- Output Generation: 가장 확률이 높은 단어를 선택(Argmax)하거나, 확률 분포에 따라 무작위로 추출(Sampling)하여 최종적으로 Token ID를 뱉어낸다. 이 ID를 다시 디코딩하면 우리가 읽을 수 있는 텍스트가 된다.
2.6 The Shift to Decoder-Only
현재의 LLM(GPT, Llama 등)은 대부분 Decoder-Only 구조를 채택하고 있다. 왜 Encoder가 사라졌을까?
BERT와 같은 Encoder-Only 모델은 '이해(Understanding)'에 강하지만, '생성(Generation)'은 Decoder의 영역이다.
GPT-1부터 시작된 연구들은 **"충분히 많은 데이터를 학습하면 Decoder만으로도 우수한 이해와 생성이 가능하다"**는 것을 증명했다. 특히, 입력(Prompt)과 출력(Response)을 구분하지 않고 하나의 시퀀스로 처리하는 것이 학습 및 추론 효율성(KV Cache 관리 등) 측면에서 유리하기 때문에, 현대의 GenAI는 거대한 Decoder 블록들의 적층 구조로 정착하게 되었다.
3. Scaled Dot-Product Attention (행렬 연산의 모든 것)
Transformer의 심장인 Attention을 직접 연산하는 과정인 Scaled Dot-Product Attention의 내부를 행렬 차원(Dimension) 단위로 뜯어보도록 하겠다.
특히 시스템 엔지니어링 관점에서는 “그래서 어떤 연산을 진행하는가?”, 즉 이 연산의 흐름을 이해하는 것이 성능 최적화의 첫걸음이다.
수식:
**3.1 변수 정의 및 행렬 차원 (Shape Analysis)**
설명의 편의를 위해 다음과 같이 하이퍼파라미터를 가정합니다.
- Batch Size () = 1 (단일 요청에 대한 연산 흐름을 확인하겠다.)
- Sequence Length () = 10 (입력 토큰 수) (해당 요청에 10개의 단어가 포함되어 있다.)
- Hidden Dimension () = 512 (모델에서 처리하려는 각 Token 벡터의 사이즈가 512이다.)
- Number of Heads () = 8 (각 벡터의 512 차원을 8등분하여 각각의 Head가 특화된 담당을 갖겠다는 뜻이다.)
- Head Dimension () = 64 (전체 벡터의 사이즈를 Head의 개수로 나누어서 각 Head가 차지하는 사이즈를 의미한다.)
**3.2 연산 과정 상세 (Step-by-Step)**
Step 1: Q, K, V Projection
입력 벡터 (
[1, 10, 512])에 가중치 행렬 를 곱해 Query, Key, Value를 만든다.Multi-Head Attention이므로, 이를 헤드 개수()만큼 쪼갠다.
- Shape:
[B, L, d_model][B, h, L, d_k] - 결과 Q, K, V Shape:
[1, 8, 10, 64]
- Shape:
Step 2: Score Matrix Calculation ()
Query와 Key를 내적(Dot-Product)하여 단어 간의 연관성(Score)을 구한다.
- Operation:
[1, 8, 10, 64][1, 8, 64, 10](K Transposed) - 결과 A Shape:
[1, 8, 10, 10] - 이
[10, 10]행렬은 10개의 단어가 서로가 서로에게 얼마나 **집중(Attention)**해야 하는지를 나타내는 Map으로 **“Attention Score”**라고도 부른다.
- Operation:
Step 3: Scaling & Softmax ()
가 커질수록 내적 값이 커져 Softmax의 기울기가 소실되는(Gradient Vanishing) 문제를 막기 위해 로 나눈다.
그 후 Softmax를 취해 확률값(0~1)으로 변환한다.
결과 S Shape:
[1, 8, 10, 10](변화 없음, 값만 정규화됨)Step 4: Weighted Sum ()
구해진 확률값(S)을 가중치로 하여 Value(V) 정보를 합친다.
- Operation:
[1, 8, 10, 10][1, 8, 10, 64](V) - 결과 Y Shape:
[1, 8, 10, 64]
- Operation:
Step 5: Concat & Output Projection
모든 헤드의 결과를 다시 합치고(), 출력 가중치 행렬 를 곱합니다.
- Concat:
[1, 8, 10, 64][1, 10, 512] - Projection:
[1, 10, 512][512, 512][1, 10, 512] - Point:
- 다시 입력의 사이즈(
[1, 10, 512])로 되돌아 왔다. - 따라서 이 블록을 다음 Layer의 input으로 그대로 사용하여 번 쌓을 수 있는 것입니다.
- Concat:
**4. Attention Mechanism의 진화: MHA, MQA, GQA**
메모리 대역폭(Memory Bandwidth)이 병목이 되는 현대의 LLM 추론 환경에서, KV Cache의 크기를 줄이는 것이 핵심 과제가 되었다.
- MHA (Multi-Head Attention):
Transformer 원본 논문의 방식.
모든 Head가 각자의 Q, K, V를 가짐.
문제점: 추론 시 KV Cache가 너무 커짐 (VRAM 부족 및 대역폭 병목).
- MQA (Multi-Query Attention):
모든 Head가 하나의 K, V를 공유.
서로의 Token에 대해서 확인해야 하므로 Query는 무조건 서로 달라야 하기 때문서 모든 Head의 Query 가중치는 다르게 설정했지만, 각 Head에서 사용하는 K, V는 동일하게 설정한다.
Q가 서로 다르기 때문에 전체 Attention 연산 결과 역시 각 Head마다 차이가 있다. (본인 담당을 Query 가중치를 통해 표현하는 것)
장점: KV Cache 크기를 로 획기적으로 줄임. 속도 빠름.
단점: 성능(정확도) 하락 가능성. → 각 Head가 더 디테일하게 표현하지 못함
- GQA (Grouped-Query Attention):
Llama 2, 3 등 최신 모델의 표준.
Head를 몇 개의 그룹으로 묶고, 그룹 내에서만 K, V를 공유.
모든 Head의 K, V가 다 똑같은 것 보다는, 일부끼리는 차이를 둬서 조금이나마 디테일을 살리는 방법
결론: MHA의 성능과 MQA의 속도 사이의 Sweet Spot.
**5. Feed Forward Network (FFN) & Activation Functions**
Attention이 단어들 사이의 관계(Global)를 파악한다면, FFN은 각 위치(Position)의 정보를 개별적으로 가공하고 확장하는 역할(Local)을 한다.
**5.1 Structure**
내부적으로 [확장 변환 **축소]**의 3단계 파이프라인을 표현한 식이다.
- Expansion (확장):
- 입력 벡터 (차원 )를 가중치 행렬 과 곱해 더 큰 차원(, 보통 4배)으로 Scaling한다.
- 여기서 은 학습을 통해 결정되는 **모델 파라미터(Model Parameters)**로, GPU 메모리에 저장된 고정값
- Non-Linearity (비선형 변환):
확장된 2048차원 벡터의 각 원소에 **활성화 함수(ReLU, GELU 등)**를 통과시킨다.
단순한 선형 결합(곱하기, 더하기)만으로는 풀 수 없는 복잡한 패턴을 학습하게 만드는 핵심 단계이다.
- Projection (축소):
변환된 정보를 다시 원래 차원()으로 압축하여 다음 레이어로 전달한다.
**5.2 Why Expand? (왜 굳이 확장하는가?)**
메모리와 연산량을 낭비하면서까지 차원을 4배나 키우는 이유는 무엇일까?
이는 "고차원에서의 분리 가능성(Linearly Separable in Higher Dimension)" 때문이다.
Untangling the Knot (매듭 풀기):
2차원 평면에서 꼬여있는 두 실타래(데이터 분포)는 풀기 어렵지만, 이를 3차원 공간으로 들어 올리면 쉽게 분리할 수 있다.
마찬가지로, 낮은 차원()에서는 겹쳐 있어서 구분이 안 되는 복잡한 의미 정보들을, 훨씬 넓은 공간()으로 펼쳐놓고 보면(Expansion) 활성화 함수가 명확하게 패턴을 분류하고 특징을 잡아낼 수 있다.
**5.3 Activation Functions의 변화**
FFN 내부에서 데이터의 복잡한 패턴을 학습하게 해주는 활성화 함수는 시간이 지남에 따라 더 부드럽고, 더 효율적인 형태로 진화했다.
- ReLU (Rectified Linear Unit)
- 수식:
- 사용 모델: Original Transformer (2017)
- 가장 직관적이고 연산이 빠르다. 양수는 그대로 통과시키고, 음수는 가차 없이 0으로 만든다.
- 한계: 입력이 음수면 기울기(Gradient)가 아예 0이 되어 버려, 해당 뉴런이 죽어버리는(Dying ReLU) 현상이 발생 → 학습 중에 일부 뉴런이 영구적으로 비활성화되는 문제
- GELU (Gaussian Error Linear Unit)
- 수식: (는 정규분포의 누적분포함수)
- 근사식:
- 사용 모델: BERT, GPT-2, GPT-3
- 진화 포인트 (Smoother):
- ReLU의 꺾인 부분(0점)을 부드러운 곡선으로 표현
- 단순히 0으로 자르는 것이 아니라, **"입력값의 크기에 따라 확률적으로 값을 살릴지 말지 결정한다"**는 개념을 도입
- 음수 영역에서도 미세한 기울기를 허용하여 ReLU의 '죽는 현상'을 방지하고 최적화(Optimization)를 더 안정적으로 표현
- SwiGLU (Swish Gated Linear Unit)
수식:
- 여기서 (=SiLU)
사용 모델: PaLM, Llama 2, Llama 3 (현재 SOTA 모델들의 표준)
진화 포인트 (Gating Mechanism):
- 활성화 함수 자체의 변화라기보다는 구조적 변화 입력을 두 갈래( 경로와 경로)로 분리
- 하나는 Swish 활성화 함수를 통과시키고, 하나는 그냥 통과시킨 뒤 둘을 곱한다(Element-wise Product).
Gate 역할:
마치 수도꼭지(Gate)처럼, 데이터의 흐름을 통제.
Swish를 통과한 값이 0에 가까우면 정보를 차단하고, 1에 가까우면 정보를 통과
단순히 비선형성을 주는 것을 넘어 **"어떤 정보를 통과시킬지 스스로 학습"**하는 능력이 탁월해 성능이 비약적으로 향상됨
Conclusion
"Attention Is All You Need"는 단순한 논문을 넘어, 우리가 데이터를 처리하는 방식을 순차적(Sequential)인 관점에서 병렬적(Parallel)이고 관계지향적(Attention-based)인 관점으로 완전히 바꾸어 놓았다.
Transformer 구조가 확립되지 않았다면 현재의 GPU, TPU 등의 성능을 잘 활용하지 못했을 것이며, 빠른 연산으로 LLM의 성능을 끌어올리는 발전 역시 이뤄낼 수 없었을 것이다.
앞으로 진행할 LLM Serving에서 사용되는 거의 모든 모델들의 근간을 파악했으며, 이런 과정, 연산을 진행하기 때문에 각 모델들을 실행할 때 어느 부분에 대해서 분석하고 개선할지, 그리고 모델의 실행에서 각 실행이 어떻게 구성되어 있는 것인지 이해하기 위한 핵심을 다루었다.
해당 구조를 기반으로 어떻게, 그리고 왜 LLM Serving을 발전 시키는 것인지 확인하면 Transformer 구조의 위대함을 계속해서 깨닫게 될 것이다.