vLLM이란 LLM의 추론(Inference) 속도를 극대화하고, 메모리 사용량을 최적화하기 위해 개발된 “Serving System” 오픈소스 라이브러리이다.
추론(Inference) vs 학습(Training)
LLM 모델을 학습하는 것과 추론 하는 것의 차이에 대해서 짚고 넘어가자.
- LLM 모델의 학습: 이미 준비된 수많은 데이터(즉, 정답을 알고 있는 데이터)를 가지고 그 데이터들의 특성을 분석하고, 데이터 사이의 관계를 가장 잘 표현할 수 있는 가중치(Weight)를 찾는 과정. 따라서 학습된 결과는 각 모델의 가중치(Weight)가 결정된 것.
→ ‘새로운 모델이 개발되었다’ == ‘새로운 가중치를 가진 모델이 완성되었다’ - 추론: 이미 학습이 완료되어 완성된 가중치를 이용해서, 새로운 데이터가 왔을 때 그에 맞는 답변을 생성해내는 것.
각각에 초점이 맞춰진 모델/Serving System이 따로 존재하기 때문에 그 차이를 이해하고 넘어가고자 한다.
vLLM은 (물론 둘 다 가능하지만)Inference 상황에서 더 강력한 효과를 보인다.
- LLM 모델의 학습: 이미 준비된 수많은 데이터(즉, 정답을 알고 있는 데이터)를 가지고 그 데이터들의 특성을 분석하고, 데이터 사이의 관계를 가장 잘 표현할 수 있는 가중치(Weight)를 찾는 과정. 따라서 학습된 결과는 각 모델의 가중치(Weight)가 결정된 것.
Introduction
[배경: 트래픽의 증가와 비용의 문제]
LLM이 로컬에서 단일 실행되는 것을 넘어 실제 서비스(Hosted Service: Programming assistant, Chatbot etc.)로 전환되면서, 다수의 동시 접속자(Concurrency)를 감당해야 할 필요성이 급증하였다. 이는 수많은 Request를 효율적인 순서로 처리할 것을 요구했으며, LLM은 모델 자체의 크기가 워낙 커서 GPU 메모리(VRAM) 자원이 걸림돌이 되었다.
[문제: 기존 엔진의 한계]
기존의 추론 방식이나 초기 엔진(FasterTransformer 등)이 다수의 요청이 들어올 때, 그것을 어떤 순서로 처리할 것인지에 대한 Scheduling은 이미 최적화를 했다(Orca의 Continuous Batching).
하지만 그것들은 여전히 들어올 때마다 메모리를 정적으로 할당했다. 이로 인해 실제 사용되지 않는 빈 공간이 생기는 **메모리 단편화(Fragmentation)**가 발생했고, GPU 메모리의 60~80%가 낭비되었다.
이는 낮은 처리량(Throughput)으로 GPU의 한계를 발생하였다.
[해결: vLLM의 등장]
이를 해결하기 위해 Megatron-LM이 제안한 ‘Parallel 연산’ 개념과, Orca가 제안한 '연속적 배칭(Continuous Batching)' 개념에, 운영체제의 페이징 기법을 도입한 PagedAttention을 결합하여 vLLM이 탄생.
[발전 흐름]
- Latency 최적화: FasterTransformer (NVIDIA, 연산 속도 중심)
- Scheduling 혁신: Orca (마이크로소프트, 스케줄링 효율화 제안)
- Memory 혁신: vLLM (메모리 파편화 해결, 사실상의 표준 등극)
- 현재 (다각화): TGI (HuggingFace, 서빙 편의성 강화), SGLang (복잡한 추론 패턴 최적화)
핵심 기술: PagedAttention
LLM이 텍스트를 생성할 때는 이전에 생성된 토큰들의 정보를 담은 **'KV Cache(Key-Value Cache)'**라는 데이터를 GPU 메모리에 저장해야 한다.
이것을 운영체제(OS)의 가상 메모리 관리 기법인 **페이징(Paging)**에서 아이디어를 얻어, 메모리를 불연속적인 블록으로 나누어 효율적으로 관리하는 알고리즘이다.
- 작동 원리: KV Cache 데이터를 연속된 메모리 공간에 저장하지 않고, '페이지' 단위로 쪼개어 비연속적인 메모리 공간에 저장
- 효과: 메모리 조각화(Fragmentation)를 거의 완벽하게 제거하여 메모리 낭비를 줄입니다. 남는 메모리 공간을 활용해 더 많은 요청(Batch)을 동시에 처리 가능
효과
제한된 vRAM을 알뜰하게 사용하여 더 많은 사용자의 대화 정보(KV Cache)를 메모리에 올릴 수 있게 되었다. 덕분에 한 번에 더 많은 요청을 묶어서(Batching) 처리하는 것이 가능해져 전반적인 처리량(Throughput)이 개선되었다. 이는 많은 요청이 들어와도 줄 서서 기다리는 시간을 줄여주므로, 결과적으로 지연 시간(Latency) 감소 효과로 이어진다.
Architecture Overview
위 사진의 모든 구성요소를 포괄하여 vLLM Serving Engine이라 부른다.
이 vLLM을 배포하고, 실행할 수 있는 docker, kubernetes 등의 환경을 포함하면 vLLM Serving System이라고 부른다.
Entrypoints
vLLM에서 활용할 수 있는 Entrypoint는 두 가지가 있다.
- Offline Inference: LLM class
파이썬 스크립트 내에서 직접 모델을 로드하고 데이터를 처리할 때 사용
- Inference(추론 상황) - Online Serving: AsyncLLMEngine
모델을 서버로 띄워 놓고 외부 요청을 받을 때 사용
※ Offline Inference vs Online Inference
Offline: 이미 데이터를 모두 알고 있어서 스크립트 내에서 데이터를 넘겨주는 경우, Training 상황을 포함. → 필요에 따라서는 이미 데이터를 알고 있으니까 결과론적으로 최적화하여 성능을 끌어올릴 수 있음.
Online: 어떤 요청/데이터가 들어올지 알 수 없는 상황, 서버에서 전달하는 ‘처음 보는’ 데이터를 처리. 예상할 수 없기 때문에 일반화 되어 있어야 하며 정확한 알고리즘이 필요함.
※ OpenAI-Compatible API Server: OpenAI의 API와 동일한 규격(인터페이스)을 제공하는 웹 서버 → 외부에서 들어오는 HTTP 요청을 받아 vLLM 엔진(LLMEngine)에 전달하고 생성된 텍스트를 다시 반환할 때 주소(Base URL)만 vLLM 서버로 바꾸면 그대로 사용 가능
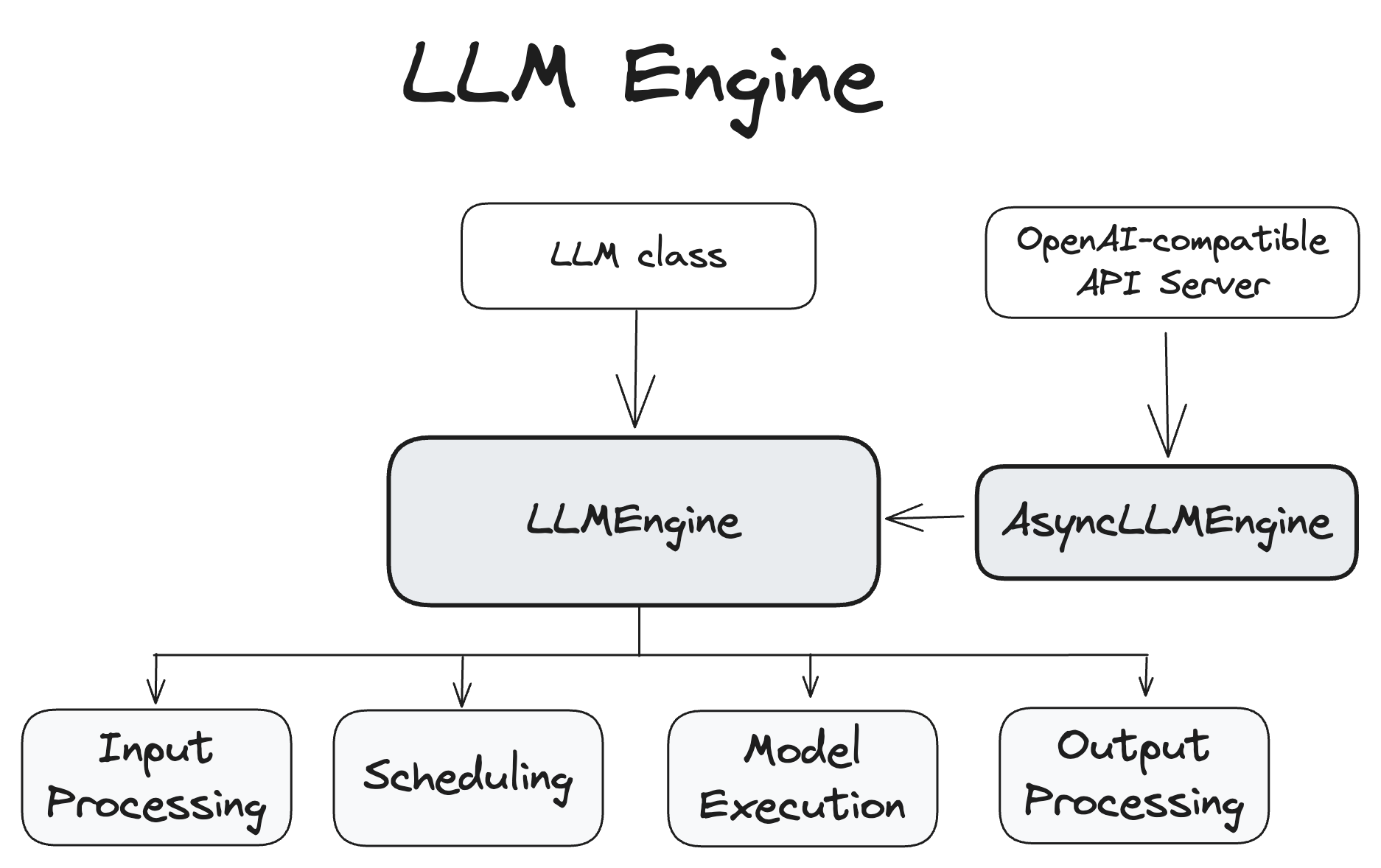
LLM Engine
Entrypoint를 통해 들어온 요청들을 실질적으로 처리하는 vLLM의 Core 부분
- Input Processing
- Tokenization: 사용자의 텍스트 요청(Prompt)을 모델이 이해할 수 있는 숫자 형태인 Token ID 리스트로 변환.
- Metadata 생성: 요청 처리에 필요한 기본 정보들을 세팅.
- Sampling Parameter
- n: parallel Sampling에서 총 몇 개의 답변을 생성할지 결정
- top_k / top_p: 후보군에서 선택 방법 - 개수 / 비율
- stop_token_id , max_tokens
- Scheduling info
- arrival_time, request_id, priority
- Sequence State
- 현재 요청이 Prefill인지 Decoding인지, 어떤 상태인지, 즉 얼마나 진행되었는가 를 표현
- prompt_token_ids, output_token_ids, context_len, status
- Scheduling
- KV Cache Management:
Block Table을 이용하여 KV Cache를 Block단위로 관리하여 요청들을 처리할 공간을 확보.
(VRAM안에 요청들을 처리할 공간이 있어야 Batch를 구성하여 처리할 수 있음)
※ KV Cache: LLM모델의 근간이 되는 Transformer에서 Attention을 계산하기 캐싱되는 데이터 (Transformer 구조 관련 글에서 상세하게 설명 예정) (vLLM에서 매우 핵심적인 대상!)
- Continuous Batching:
Orca의 Iteration-level scheduling을 적용.
요청이 끝날 때까지 기다리지 않고, 토큰 생성 단위로 스케줄링하여 빈 메모리 공간에 새로운 요청을 즉시 끼워 넣어 배치 효율을 극대화.
- Model Execution
실행 명령을 받은 Batch를 실제 모델을 이용해서 처리하는 단계
- Parallelism: Megatron-LM의 병렬 연산 기법 활용
FatsterTransformer등 기존 엔진에서도 채택했던 병렬화 개념인 Pipeline Transformer와 Tensor Transformer를 구현하여 Throughput과 latency를 최적화
- PagedAttention Kernel:
vLLM의 핵심 기술인 PagedAttention이 적용된 커널을 활용하여 **흩어져 있는 메모리 조각(Non-contiguous memory)**에서 효율적으로 Attention 연산을 수행하는 Custom CUDA Kernel 실행.
- Output Processing
- Sampling: 모델이 계산한 확률값(Logits)을 바탕으로 설정(Temperature 등)에 맞춰 다음 Token ID를 선택.
- Detokenization: 선택된 Token ID를 다시 사람이 읽을 수 있는 텍스트로 변환하여 반환.
마치며
vLLM은 Inference Engine에서 메모리 효율성에서 혁신을 일으켰다.
그 방법의 핵심은 PagedAttention을 통한 **“불연속적인 메모리 관리”**이다.
덕분에 4GB VRAM을 가진 나의 GTX 1650 같은 환경에서도, Llama-3.2-3B와 같은 최신 모델을 훨씬 더 빠르고 효율적으로 서빙할 수 있게 된 것이다. (과거엔 메모리 부족으로 툭하면 멈췄을 상황에서도 말이다!)
(누군가의 요청에 따라) vLLM과 관련된 글만 10개 이상 작성할 예정이므로 해당 글에서는 간단하게 vLLM이 대충 어떤 것이고, 왜 필요하게 되었으며, 어떤 구조로 구성되어 있는지 알아보고,
앞으로 차차 새로운 글이 등장하게 된다면 가끔 되돌아와서 “이 부분이 이렇게 구성된 것이구나!”라고 이해하는 것이 가장 이상적인 목표이다.
vLLM 마스터를 향한 발걸음을 시작해보자.
참고 자료
%28clear%29_Efficient_Memory_Management_for_LLM_Serving_with_PagedAttention.pdf