vLLM을 사용하고 연구할 때는, vLLM을 활용해서 LLM 서빙을 더욱 효율적으로 하겠다는 목표를 가지고 있을 것이다.
그런데 실질적으로 vLLM을 활용할 때 어떤 성능이 나오고, 어느 부분에서 여전히 개선이 필요한지 확인하는 과정은 필수로 선행되어야 한다.
따라서 “실제로 어떤 구조로 vLLM이 실행되는거지?”, "왜 토큰 생성이 느리지?", "GPU 메모리는 충분한가?" 같은 질문에 답하기 위한 정확한 측정이 선행되어야 한다.
따라서 이번 글에서는 vLLM의 성능을 분석하는 다양한 프로파일링 도구들을 소개하고, 실제 실험(Block Size 최적화)을 통해 데이터를 어떻게 수집하고 분석하는지 그 과정을 상세히 공유하고자 한다.
1. vLLM Profiling 도구의 계층적 이해
프로파일링 도구는 저마다 바라보는 '깊이(Level)'가 다르다. 마치 숲을 보는 드론과 나무를 보는 현미경이 다른 것처럼.
vLLM 프로파일링은 크게 4가지 계층으로 나눌 수 있다. 상위 레이어에서 전체적인 흐름을 파악하고, 점차 하위 레이어로 내려가며 병목 지점을 찾는 것이 정석이다.
- vLLM Metrics (최상위 레이어):
- 특징: vLLM 서버가 자체적으로 제공하는 실시간 통계 정보
- 제공 데이터: 처리량(Throughput), 지연 시간(Latency, TTFT), 캐시 사용률(Cache Usage), 대기열 길이(Queue Length) 등.
- 용도: "지금 서비스가 느린가?", "메모리가 부족한가?" 같은 거시적인 상태 파악.
- PyTorch Profiler (프레임워크 레이어):
- 특징: PyTorch 레벨에서 연산자(Operator) 단위의 실행 시간을 측정
- 제공 데이터: 각 함수(Attn, MLP 등)의 실행 시간, CPU/GPU 간 데이터 이동 등.
- 용도: 어떤 PyTorch 연산이 시간을 많이 잡아먹는지, CPU 오버헤드는 없는지 확인.
- Nsight Systems (시스템 레이어):
- 특징: OS, CPU, GPU, 커널, API 호출 등 시스템 전체의 타임라인을 시각화
- 용도: CPU-GPU 간 동기화 지연, 커널 실행 간의 유휴 시간(Gap) 등을 핀셋으로 집어내듯 분석.
- Nsight Compute (커널 레이어):
- 특징: GPU 커널 하나를 뜯어서 하드웨어 레벨(SM, Memory Bandwidth 등)의 효율을 분석합니다.
- 용도: "이 커널이 Compute Bound인가, Memory Bound인가?"를 판별하여 최적화 방향 결정.
핵심 전략: 목표에 적합한 결과를 찾기 위해서는 무작정 Nsight부터 켜기보다는, vLLM Metric으로 거시적인 문제를 찾고, 필요에 따라 더 깊은 도구를 꺼내 드는 것이 효율적이다.
vLLM과 프로파일러 사이의 관계
실제 LLM을 실행하고 서빙하는 vLLM과, 그 과정에 대한 데이터를 뽑아내는 profiler는 어떤 관계로 구성되는 것일까
- vLLM 프로세스 내부에서 실행
상위 레이어에서 검증하는 vLLM Metric과 Pytorch Profiler는 vLLM이 실행되는 프로세스 내부에서 같이 돌아간다.
vLLM Metric의 경우에는 사실 말할 것도 없이, 애초에 돌아가는 프로세스에서 내부 변수를 업데이트 하는 것만으로 실행이 가능하다.
따라서 vLLM의 실행시에 HTTP 엔드포인트 (:8000/metric )를 통해 저장되고 있는 내부 변수를 직접 확인할 수 있다.
하지만 그것을 직접 열어본다면 엄청나게 많은 숫자들의 향연일 뿐 이해할 수도 분석할 수도 없다.
따라서 해당 엔드포인트로 전달 되는 데이터를 독립적인 클라이언트로 Prometheus와 Grafana라는 별개의 프로세스에서 요청(Scraping)해서 활용한다면 Metric을 시각화 하는 것도 가능하다. (실습 과정에서 구체적으로 확인 가능)
vLLM Architecture에서 확인했듯 vLLM에서 Pytorch 라이브러리를 호출하여 LLM 실행에 활용한다. 그 때 Pytorch Profiler 역시 동일 프로세스 내 공유 라이브러리 (Shared Library)의 형태로 프로파일러 코드도 함께 메모리에 올라가서 실행된다.
그 후 vLLM을 실행한다면 vLLM 프로세스 내부의 파이토치 엔진이 CUDA 드라이버 API 호출 지점에 갈고리(Hook)을 걸어 실행 시간을 기록하는 Hooking 방법으로 프로파일링을 실행한다.
- 부모-자식 관계로 Wrapper 모델로 실행
nsys와 ncu는 vLLM 내부 프로세스에서 같이 실행되는 것이 아니라 더 상위에서 실행되고 있는 부모 프로세스의 형태이다.
nsys profile vllm serve … 명령어를 통해 nsys 를 먼저 실행시키면 부모 프로세스가 되고, 그 안에서 vLLM이 Fork/Exec를 통해 자식 프로세스로 실행된다.
그러면 nsys가 vLLM 프로세스의 메모리 공간에 자신의 측정 라이브러리(.so 파일)을 강제로 주입하여 중간 과정 정보를 따로 저장하는 것이다.
따라서 Wrapper 형태를 위해 반드시 vLLM보다 먼저 실행되어야 한다.
성능 관점을 간단하게 살펴보면
vLLM Metric은 간단한 변수 연산만 진행하면 되기 때문에 Overhead가 거의 없다.
Nsight를 사용할 때는 부모 프로세스가 자식을 멈추고 제어하기 때문에 실행 속도가 극단적으로 느려진다.
특히 ncu는 vLLM의 실행 과정에서 정보만 기록하는 것이 아니라 특정 커널 연산이 일어날 때 자식 프로세스를 잠시 멈추고 하드웨어 카운터를 읽기 위해 해당 연산을 여러 번 다시 실행하기도 한다. 따라서 간단한 연산 시나리오라도 엄청난 시간이 걸린다. (이번 글에서 nsys, ncu를 작성하지 못하는 이유이기도 하다 ,,,)
특히
ncu는 vLLM의 실행 과정에서 정보만 기록하는 것이 아니라 특정 커널 연산이 일어날 때 자식 프로세스를 잠시 멈추고 하드웨어 카운터를 읽기 위해 해당 연산을 여러 번 다시 실행하기도 한다. 따라서 간단한 연산 시나리오라도 엄청난 시간이 걸린다. (이번 글에서nsys,ncu를 작성하지 못하는 이유이기도 하다 ,,,)vLLM Metric은 외부에서 데이터를 가져가는 Pull 방식, Pytorch Profiler는 내부에서 파일로 내뱉는 Push 방식, Nsight는 실행 경로를 추적하는 Tracing 방식으로 각자 Layer에서 실행 가능한 형태로 데이터를 제공한다.
2. 실험 시나리오 설계: "무엇을 보고 싶은가?"
vLLM을 실제로 실행하고 그 과정을 분석해보는 실행 예제를 살펴보도록 하겠다.
**"Block Size 설정이 vLLM 성능에 미치는 영향"**을 분석하는 과정을 진행하고자 한다.
vLLM의 핵심 기술인 PagedAttention은 KV Cache를 Block 단위로 관리하여, 불연속적인 데이터를 활용할 수 있게 되었다. 이는 메모리에 불필요하게 남아 있는 애매한 빈 공간들, 예를 들어 10칸 사이즈의 요청이 메모리에 들어오고 싶지만, 5칸/5칸으로 끊어져 있다면 10칸 묶음은 들어오지 못하는 외부 단편화(External Fragmentation)을 해결했다.
하지만 Block Size가 커지면 비어있는 외부 공간과 무관하게 하나의 Block 내부에 비어있는, 마치 질소 포장과 같은 빈 공간이 생기게 된다. 이것은 내부 단편화(Internal Fragmentation을 발생시키기 때문에 적절한 Block Size의 설정이 필요하다.
따라서 Block Size는 메모리 효율성에 지대한 영향을 미치는 파라미터이므로 그 영향력을 직접 확인하기 위해 프로파일링을 진행해야 한다.
2.1. 시나리오 변수 설정
실험의 목적을 달성하기 위한 변인을 설정해야 한다.
- Block Size (Block): 16, 32, 64, 128, 256 (실험의 핵심 변수)
- vLLM에서 공식적으로 제공하는 최적의 Block Size는 16이다. 따라서 Block Size가 증가할수록 성능이 저해되는 부분이 분명히 존재할 것이고, 그 지점을 찾는 것이 이번 시나리오의 목표이다.
- 해당 이유로 Block Size가 16보다 작은 경우는 평가하지 못했는데, 추후 직접 커널을 수정해서 새로 빌드할 수 있는 능력이 생긴다면 추가적으로 실험을 진행하고 결과를 비교할 것이다.
- Dataset: ShareGPT (실제 대화형 데이터 분포 반영)
- Input Token Length: 128, Output Token Length: 300, 1000 Prompts
- Tip: Internal Fragmentation(내부 단편화)을 극대화하여 관찰하려면, Block Size의 배수가 아닌 애매한 길이(예: 260 토큰)를 사용하는 것이 좋다.
- Request Rate: Infinite (무한대)
- 시스템의 한계 성능(Throughput)을 측정하기 위해 극한까지 요청을 보낸다.
- 메모리 제약: GPU Memory Utilization 0.4 (40%) vs 0.9 (90%)
- 메모리 자원이 귀한 상황과 풍부한 상황을 비교하여 각각의 상황에서 나타나는 특징을 관찰한다.
2.2. 가설 설정
해당 실험을 진행하며 보이고자 하는 가설은 다음과 같다.
- Block Size 증가 시 Internal Fragmentation 증가로 캐시 메모리 낭비가 발생할 것이다.
- 동일 메모리 대비 처리 가능 요청수가 감소하여 처리량 저하 및 Latency가 증가할 것이다.
3. 실전 프로파일링: 대조 실험 (Memory 0.4 vs 0.9)
3.1. vLLM Metric 수집 및 시각화
가장 먼저 해야 할 일은 서버가 뱉어내는 기본 지표를 확인하는 것다.
이는 앞서 말했던 vLLM Metric을 확인하는 것으로, /metrics 엔드포인트를 통해 기본적으로 저장되고 있는 데이터를 확인할 수 있다.
3.2 **Prometheus + Grafana:**
실시간 대시보드를 구성하여 시각적으로 모니터링하기 가장 좋습니다.
Prometheus는 vLLM에서 제공하는 Metric에 대한 데이터를 저장하는 DB의 역할을 수행한다. prometheus.yml에 vLLM 타겟을 추가하고 실행하면 8000번 포트를 통해서 수집된 데이터를 확인할 수 있다. 하지만 여전히 분석하기 복잡한 수많은 숫자들의 향연이기 때문에 이것을 그래프의 형태로 수정해주는 것이 Grafana이다. Grafana를 실행시키고 prometheus 포트를 연결한다면 DB에 저장되고 있는 데이터를 시각적으로 표현해주어 수집한 vLLM Metric을 쉽게 관찰할 수 있다.
https://docs.vllm.ai/en/stable/contributing/profiling/#profiling-vllm
Prometheus 및 Grafana를 실행하는 가장 간단한 방법으로는 Docker를 이용하는 것을 추천한다.
다만 본인은 고용 서버에서 작업하므로 Docker 실행에 제한이 있어 직접 빌드하였기 때문에 그 과정에 대한 설명은 생략하도록 하겠다.
**3.3 Raw CSV Logging (커스텀):**
실험 데이터를 파일로 남겨서 엑셀이나 MATLAB, Python으로 정밀 분석할 수 있다. 별도의 파이썬 스크립트(monitor)를 띄워 /metrics를 0.1초마다 긁어옵니다.
[Code Snippet] 커스텀 매트릭 로거 (핵심 요약)
아래 코드는 vLLM의 /metrics 엔드포인트를 주기적으로 호출하여 KV Cache 사용량과 실행 중인 요청 수를 CSV로 저장하는 스크립트의 핵심 부분이다.
Python
def monitor(url, interval, output_file):
print(f"✅ Monitoring started! Target: {url}")
with open(output_file, "w") as f:
# 분석에 필요한 핵심 지표만 헤더로 저장
f.write("timestamp,kv_cache_usage,num_running\n")
while True:
try:
response = requests.get(url, timeout=1)
if response.status_code == 200:
usage, running = None, None
# 텍스트 파싱으로 필요한 지표 추출
for line in response.text.split('\n'):
# 1. KV Cache 사용률 (vLLM 버전에 따라 이름 상이할 수 있음)
if "kv_cache_usage_perc" in line and "HELP" not in line:
usage = float(line.split()[-1])
# 2. 실행 중인 요청 수 (Concurrency 확인용)
if "num_requests_running" in line and "HELP" not in line:
running = float(line.split()[-1])
# 데이터가 모이면 CSV 한 줄 기록
if usage is not None:
timestamp = datetime.now().strftime("%H:%M:%S.%f")
f.write(f"{timestamp},{usage},{running}\n")
f.flush()
except Exception:
pass # 서버가 꺼져도 죽지 않고 대기
time.sleep(interval) # Sampling Rate 조절
이 방식을 통해 초단위의 변화까지 놓치지 않고 CSV로 저장할 수 있었고, 이를 그래프로 그려본 결과 Block Size가 커질수록 Cache Usage는 100%를 찍지만 실제 처리량(Num Running)은 급감하는 '내부 단편화' 현상을 명확히 확인할 수 있다.
3.4. PyTorch Profiler 활용
vLLM 내부의 연산 병목을 확인하기 위해 PyTorch Profiler를 활용할 수 있다. vLLM은 서버 실행 시 옵션 한 줄로 프로파일러를 켜서 실행할 수 있다.
Bash
# 1. 서버 실행 시 프로파일러 설정 활성화
vllm serve meta-llama/Llama-3.1-8B-Instruct \
--profiler-config '{"profiler": "torch", "torch_profiler_dir": "./vllm_profile"}'
# 2. 벤치마크 실행 (profile 옵션 추가)
vllm bench serve ... --profile --num-prompts 2
이렇게 수집된 트레이스 파일을 통해 Attention 연산과 MLP 연산의 비중을 확인하고, CPU 오버헤드가 발생하는 구간을 식별할 수 있다.
Note: Nsight Systems(nsys)와 Nsight Compute(ncu)를 이용한 심층 분석(Prefill vs Decode 단계의 Compute/Memory Bound 분석)은 내용이 방대하여 다음 포스팅(2부)에서 자세히 다뤄보도록 하겠다.
4. 실험 결과
[실험1] 메모리 용량 제한 환경 (GPU Util: 0.4)
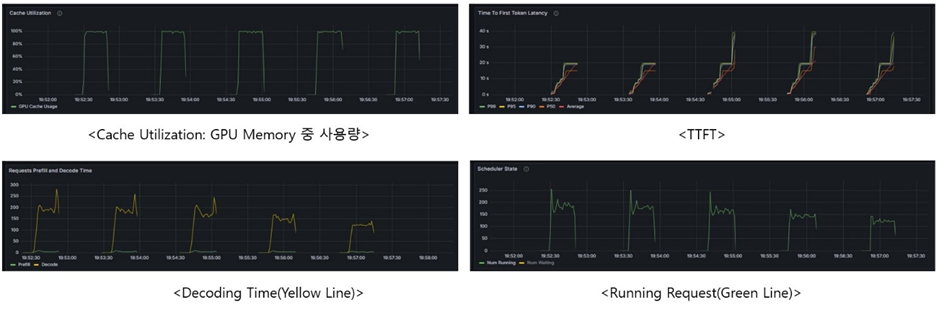
<< Prometheus + Grafana 그래프 분석 >>
- Cache Utilization(100% 도달): 적은 요청에도 할당된 캐시 메모리가 가득 참. Block Size와 무관하게 모든 메모리를 활용.
- Num Running(감소): Block Size가 커질수록 실행중인 요청 수가 감소함. 이는 Internal Fragmentation으로 인해 사용하는 메모리 대비 실제 유의미한 데이터가 적음을 확인함.
- TTFT(급증): Block Size 64부터 Block 효율 저하로 메모리가 가득 차 요청이 Queue에서 정체되는 시간이 발생함.
- Decoding Time(감소): Batch Size가 줄어들면서 개별 step의 연산 양이 감소하여 표면적인 Decoding 속도 자체는 증가함.
[실험2] 메모리 용량 여유 환경 (GPU Util: 0.9)
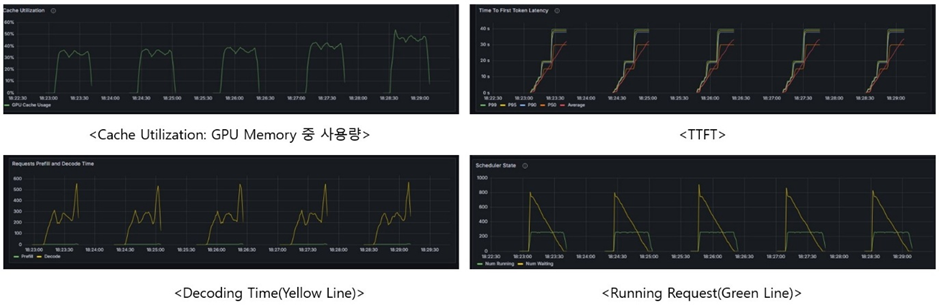
<< Prometheus + Grafana 그래프 분석 >>
- Num Running(일정): 메모리가 충분하여 Block Size가 커져도 동시에 처리하는 Request 수가 일정하게 유지됨.
- Cache Utilization(상승): 동일한 수의 요청을 처리함에도 불구하고 Block Size가 커질수록 캐시 점유율이 상승함. 이는 Internal Fragmentation으로 인해 불필요한 메모리 사용량이 증가한 것을 의미함.
- TTFT 및Decoding Time(일정): 메모리 용량의 한계에 도달하지 않아 대기가 발생하지 않으며 Batch Size가 일정하게 유지되어 Token 생성 시간이 유지됨.
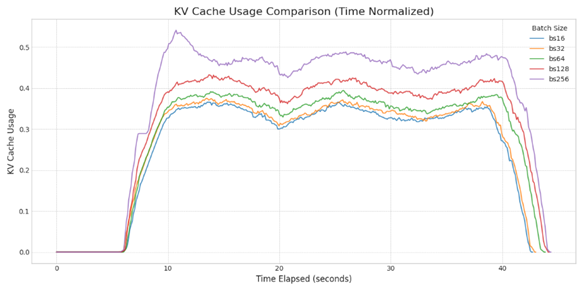
// CSV
timestamp,kv_cache_usage
...
19:52:28.538874,0.0
19:52:28.641902,0.0
19:52:28.764256,0.00434027777777779
19:52:29.077775,0.015625
19:52:29.201157,0.13585069444444442
19:52:29.304826,0.25390625
...
<< CSV Logging을 통한 데이터 수집, matlab 시각화 >>
Block Size 변화에 따라 Request 처리에 사용되는 Cache Memory 사용량을 CSV 파일로 수집한 후, matlab을 이용해서 하나의 그래프로 시각화한 것이다.
이를 통해 전체 동일한 Request를 처리하는 동안 Block Szie가 커지면 사용하는 전체 Cache Memory 사용량이 더 많아진다는 것을 분명히 확인할 수 있다.
즉, 동일한 일을 처리하는데 더 많은 자원을 소모한다 == 낭비
그 낭비는 불필요하게 메모리를 차지하고 있는 Internal Fragmentation이라는 것을 확인할 수 있다.
실험 결론
따라서 위의 실험을 통해 다음과 같은 결론을 내릴 수 있다.
- Block Size 16~32일 때 Internal Fragmentation이 최소화되어 제한된 자원에서 더 높은 Throughput을 얻을 수 있다.
- Request 부하 증가 시 메모리 공간이 부족한 경우 큰 Block Size는 급격한 TTFT 증가를 초래하고 이는 Latency 증가로 이어진다.
5. Conclusion: 프로파일링의 중요성
이번 실험을 통해 우리는 두 가지 중요한 사실을 체험할 수 있었다.
- 데이터의 상호 검증: 단순히 "느리다"는 느낌은 **Metric(최상위)**이 확인해주고, 그 원인이 "배치 사이즈 감소에 따른 착시"라는 점은 **Profiler(중간)**가 설명해준다.
- 레이어의 선택: 내부 단편화 문제를 잡기 위해 굳이 하위 레이어인 ncu까지 갈 필요는 없다. vLLM Metric 수준에서도 충분히 명확한 결론을 낼 수 있었기 때문이다.
결국 프로파일링의 핵심은 '무엇을 얻고자 하는가'에 맞는 적절한 레이어를 선택하는 것이다. 적절한 도구 선택이 수 시간의 삽질을 줄여줄 수 있다.
이번에 사용해보지 못한 ncu와 nsys는 transformer 구조의 prefill phase와 decoding phase를 비교하는 실험에서 사용해보도록 할 것이고,
기본적인 프로파일링 경험을 토대로 실질적인 가설 및 시나리오를 세워 유의미한 결과를 뽑아내는 과정을 진행할 예정이다.
참고자료
https://docs.vllm.ai/en/stable/contributing/profiling/#profiling-vllm