[Lexical Analyzer 8] From Regular Expressions to Automata
정규 표현식에서 오토마타로
이전 포스트에서 NFA와 DFA의 개념을 살펴보았다. 이제 어휘 분석기 구축의 핵심 단계인 정규 표현식에서 오토마타로의 변환을 다루겠다.
정규 표현식을 실행 가능한 어휘 분석기로 바꾸는 과정은 다음과 같다.
정규 표현식 → NFA → DFA → 어휘 분석기
이 변환 과정에서 사용되는 두 가지 핵심 알고리즘이 있다.
| 알고리즘 | 입력 | 출력 | 목적 |
|---|---|---|---|
| Thompson 구성법 | 정규 표현식 | NFA | 정규 표현식의 구조를 NFA로 직접 변환 |
| 부분집합 구성법 | NFA | DFA | NFA의 비결정성을 제거하여 DFA로 변환 |
NFA에서 DFA로의 변환 (부분집합 구성법)
부분집합 구성법(Subset Construction) 은 NFA를 동등한 DFA로 변환하는 알고리즘이다. 핵심 아이디어는 DFA의 각 상태가 NFA 상태들의 집합에 대응된다는 것이다.
ε-closure와 move 연산
부분집합 구성법에서 사용되는 두 가지 핵심 연산이 있다.
ε-closure(s) : 상태 s에서 ε-전이만으로 도달할 수 있는 NFA 상태들의 집합. 상태 s 자신도 포함된다.
ε-closure(T) : 상태 집합 T의 각 상태 s에 대한 ε-closure(s)의 합집합.
move(T, a) : 상태 집합 T의 어떤 상태 s에서 입력 심볼 a에 대한 전이로 도달할 수 있는 NFA 상태들의 집합.
부분집합 구성법 알고리즘
초기에 ε-closure(s₀)만이 Dstates에 있고, 표시되지 않음
while (Dstates에 표시되지 않은 상태 T가 있음) {
T를 표시함;
for (각 입력 심볼 a에 대해) {
U = ε-closure(move(T, a));
if (U가 Dstates에 없으면)
U를 표시되지 않은 상태로 Dstates에 추가;
Dtran[T, a] = U;
}
}
여기서 Dstates는 DFA 상태들의 집합이고, Dtran은 DFA의 전이 테이블이다. NFA의 시작 상태 s₀에 대한 ε-closure가 DFA의 시작 상태가 된다.
DFA 상태 중 NFA의 수락 상태를 포함하는 상태는 DFA의 수락 상태가 된다.
부분집합 구성법 예제
이전 포스트의 (a|b)*abb를 인식하는 NFA를 DFA로 변환해보자.
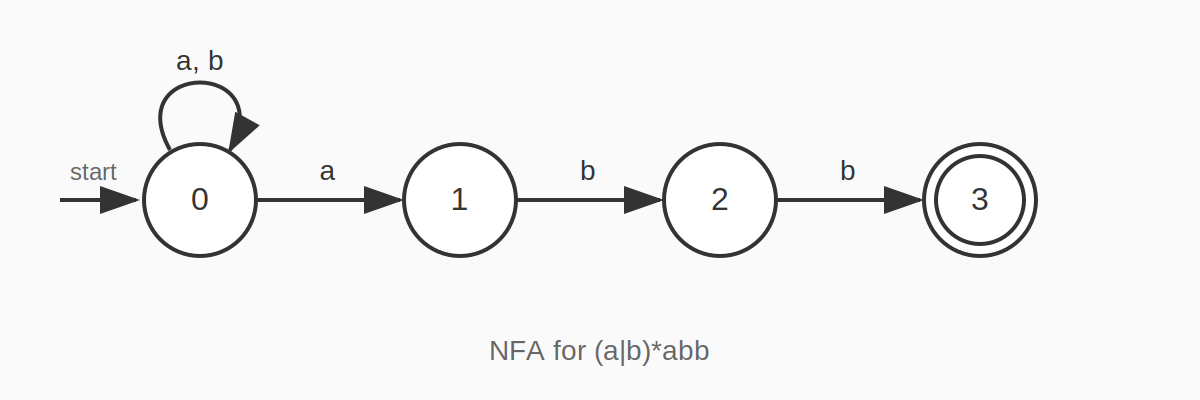
Step 1: 시작 상태의 ε-closure 계산
상태 0에서 ε-전이가 없으므로 ε-closure({0}) = {0}이다. 이것이 DFA의 시작 상태 A가 된다.
Step 2: 각 상태에서 각 입력에 대한 전이 계산
| DFA 상태 | NFA 상태 집합 | a | b |
|---|---|---|---|
| A | {0} | ε-closure(move({0}, a)) = {0, 1} = B | ε-closure(move({0}, b)) = {0} = A |
| B | {0, 1} | ε-closure(move({0,1}, a)) = {0, 1} = B | ε-closure(move({0,1}, b)) = {0, 2} = C |
| C | {0, 2} | ε-closure(move({0,2}, a)) = {0, 1} = B | ε-closure(move({0,2}, b)) = {0, 3} = D |
| D | {0, 3} | ε-closure(move({0,3}, a)) = {0, 1} = B | ε-closure(move({0,3}, b)) = {0} = A |
상태 D는 NFA의 수락 상태 3을 포함하므로 DFA의 수락 상태가 된다.
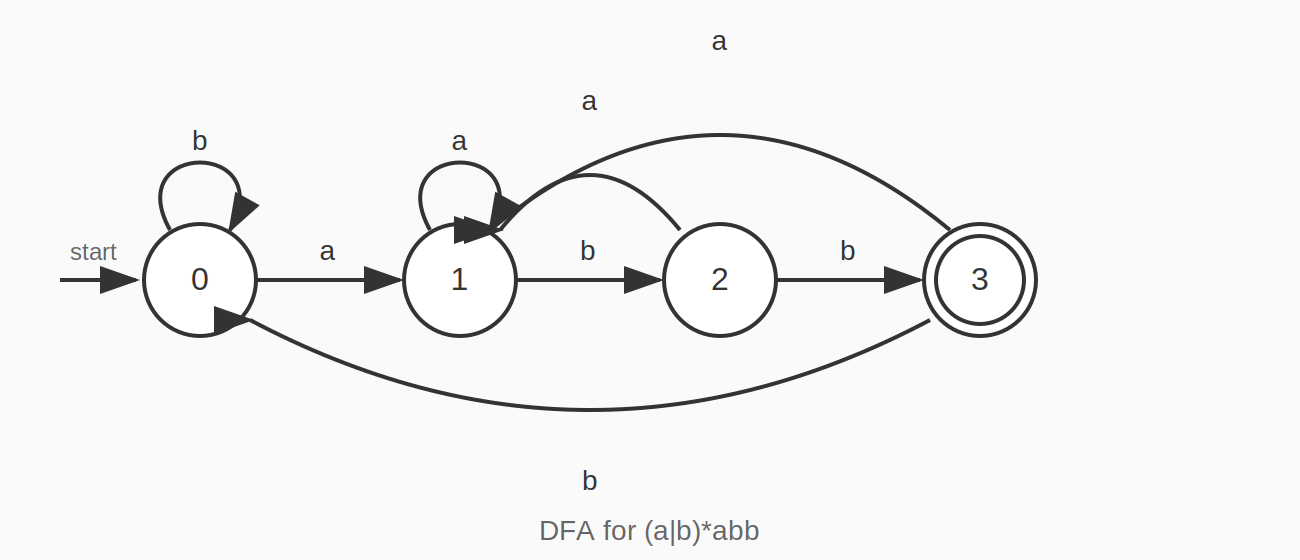
결과 DFA 전이 테이블
| STATE | a | b |
|---|---|---|
| A | B | A |
| B | B | C |
| C | B | D |
| D | B | A |
NFA 시뮬레이션
NFA를 DFA로 변환하지 않고 직접 시뮬레이션할 수도 있다. 이 방법은 부분집합 구성법과 유사한 아이디어를 사용하지만, DFA를 명시적으로 구성하지 않는다.
NFA 시뮬레이션 알고리즘
S = ε-closure(s₀);
c = nextChar();
while (c != eof) {
S = ε-closure(move(S, c));
c = nextChar();
}
if (S ∩ F != ∅) return "yes";
else return "no";
#주의..
#나도 이 코드 볼때마다 뭐였는지 생각이 안나서 10분동안 주시하다가 생각남
이 알고리즘은 현재 가능한 NFA 상태들의 집합 S를 유지하면서 입력을 처리한다. 최종적으로 S가 수락 상태를 하나라도 포함하면 입력을 수락한다.
시뮬레이션 예제: 입력 `aabb`
(a|b)*abb를 인식하는 NFA에서 입력 aabb를 시뮬레이션해보자.
| 단계 | 입력 | 현재 상태 집합 S |
|---|---|---|
| 초기 | - | ε-closure({0}) = {0} |
| 1 | a | ε-closure(move({0}, a)) = {0, 1} |
| 2 | a | ε-closure(move({0,1}, a)) = {0, 1} |
| 3 | b | ε-closure(move({0,1}, b)) = {0, 2} |
| 4 | b | ε-closure(move({0,2}, b)) = {0, 3} |
최종 상태 집합 {0, 3}이 수락 상태 3을 포함하므로 입력 aabb는 수락된다.
정규 표현식에서 NFA로의 변환 (Thompson 구성법)
Thompson 구성법(Thompson's Construction) 은 정규 표현식을 NFA로 변환하는 알고리즘이다. 정규 표현식의 재귀적 정의에 따라, 하위 표현식에 대한 NFA를 구성하고 이들을 조합하여 전체 NFA를 만든다.
Thompson 구성법으로 만들어진 NFA는 다음과 같은 특성을 가진다.
- 정확히 하나의 시작 상태와 하나의 수락 상태를 가진다.
- 수락 상태에서 나가는 간선이 없다.
- 각 상태는 최대 2개의 ε-전이 또는 1개의 심볼 전이를 가진다.
기본 규칙
규칙 1: ε (빈 문자열)
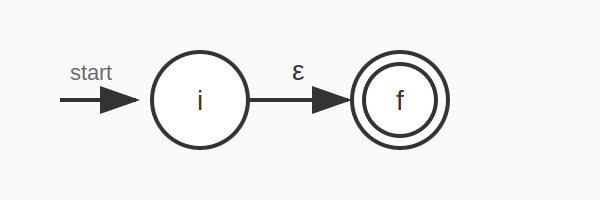
시작 상태에서 수락 상태로 ε-전이 하나만 있는 NFA를 구성한다.
규칙 2: 단일 심볼 a
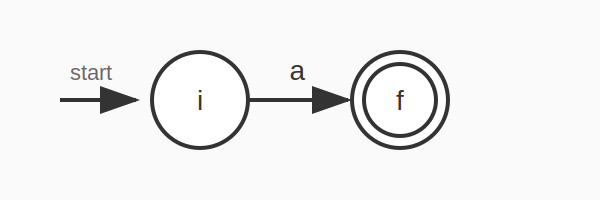
시작 상태에서 수락 상태로 심볼 a로 레이블된 전이 하나만 있는 NFA를 구성한다.
귀납적 규칙
정규 표현식 r과 s에 대한 NFA N(r)과 N(s)가 있다고 가정하자.
규칙 3: r|s (선택)
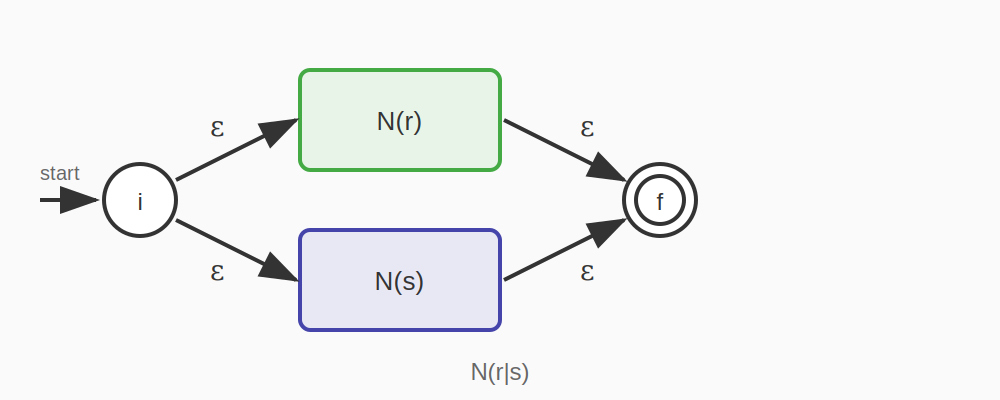
새로운 시작 상태에서 N(r)과 N(s)의 시작 상태로 각각 ε-전이를 추가하고, N(r)과 N(s)의 수락 상태에서 새로운 수락 상태로 ε-전이를 추가한다.
규칙 4: rs (연결)
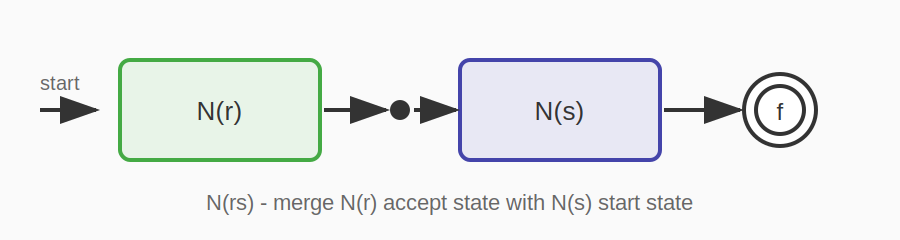
N(r)의 수락 상태를 N(s)의 시작 상태와 합친다. N(r)의 시작 상태가 전체 NFA의 시작 상태가 되고, N(s)의 수락 상태가 전체 NFA의 수락 상태가 된다.
규칙 5: r (클로저)*
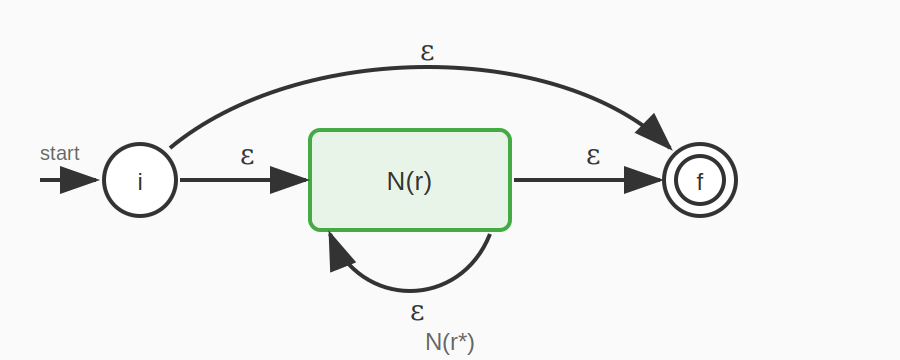
새로운 시작 상태에서 N(r)의 시작 상태와 새로운 수락 상태로 ε-전이를 추가한다. N(r)의 수락 상태에서 N(r)의 시작 상태와 새로운 수락 상태로 ε-전이를 추가한다.
Thompson 구성법 예제: (a|b)*abb
정규 표현식 (a|b)*abb를 NFA로 변환하는 과정을 단계별로 살펴보자.
Step 1: a와 b에 대한 기본 NFA 구성 (규칙 2)
Step 2: a|b에 대한 NFA 구성 (규칙 3)
Step 3: (a|b)*에 대한 NFA 구성 (규칙 5)
Step 4: (a|b)*a, (a|b)*ab, (a|b)*abb로 연결 (규칙 4)
최종 결과는 다음과 같다.
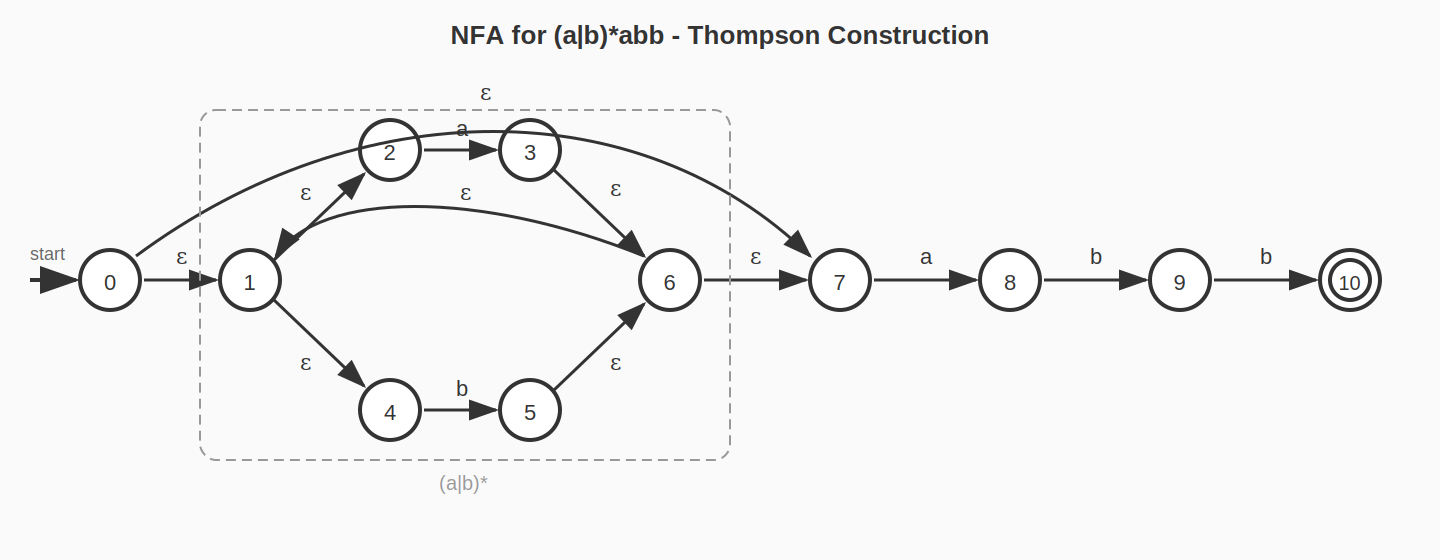
Thompson 구성법의 중요한 특징은 정규 표현식의 길이가 n일 때, 생성되는 NFA의 상태 수가 최대 2n개라는 것이다. 각 심볼이나 연산자가 최대 2개의 상태를 추가하기 때문이다.
변환 과정 요약
정규 표현식에서 효율적인 어휘 분석기를 만드는 전체 과정을 요약하면 다음과 같다.
| 단계 | 입력 | 출력 | 알고리즘 |
|---|---|---|---|
| 1 | 정규 표현식 | NFA | Thompson 구성법 |
| 2 | NFA | DFA | 부분집합 구성법 |
| 3 | DFA | 최소 DFA | DFA 최소화 (선택적) |
Thompson 구성법은 정규 표현식의 구조를 직접 반영하여 NFA를 만들기 때문에 구현이 단순하고 이해하기 쉽다. 부분집합 구성법은 NFA의 비결정성을 제거하여 효율적인 문자열 매칭이 가능한 DFA를 만든다.
실제 어휘 분석기 생성기인 Lex나 Flex는 이러한 알고리즘들을 내부적으로 사용하여 정규 표현식 명세로부터 효율적인 어휘 분석기를 자동으로 생성한다.