[Lexical Analyzer 9] Design of a Lexical-Analyzer Generator
어휘 분석기 생성기의 설계
이전 포스트에서 정규 표현식을 NFA와 DFA로 변환하는 방법을 살펴보았다. 이번 포스트에서는 Lex와 같은 어휘 분석기 생성기가 어떻게 설계되는지를 다루겠다.
어휘 분석기 생성기는 정규 표현식으로 작성된 토큰 패턴 명세를 입력받아, 실제로 동작하는 어휘 분석기 코드를 자동으로 생성한다.
생성된 어휘 분석기의 구조
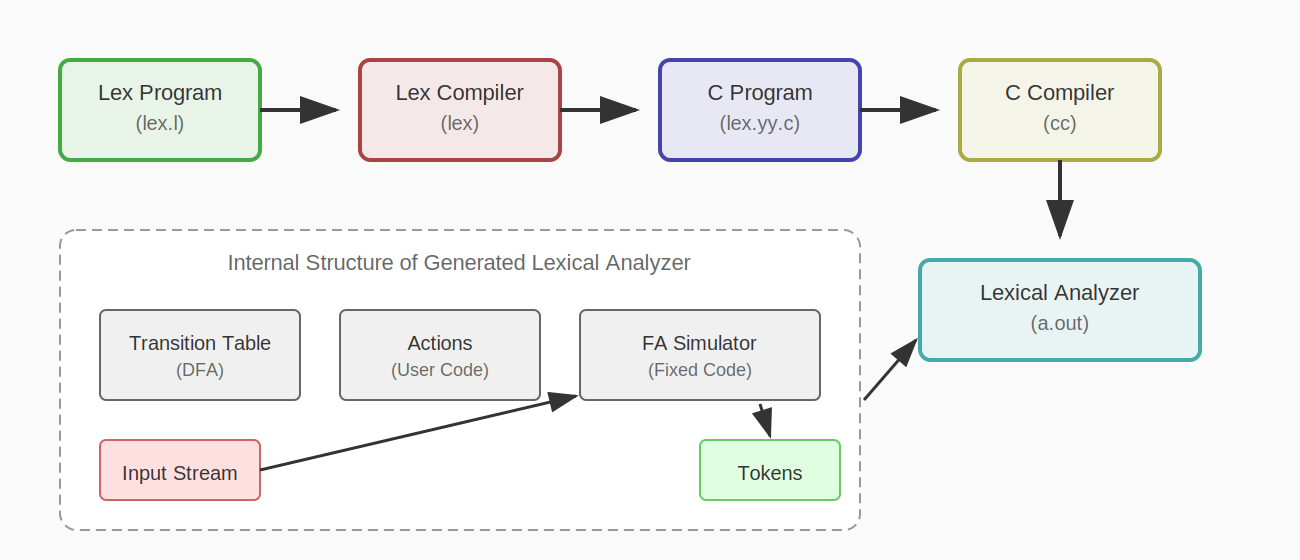
Lex가 생성한 어휘 분석기의 구조는 위 그림과 같다. Lex 프로그램은 전이 테이블과 액션으로 변환되고, 이것이 유한 오토마타 시뮬레이터와 함께 동작하여 어휘 분석기를 구성한다.
어휘 분석기는 다음과 같이 동작한다.
- 입력 버퍼에서 문자를 읽는다.
- 오토마타를 시뮬레이션하여 패턴과 매칭되는 가장 긴 접두사를 찾는다.
- 매칭된 패턴에 해당하는 액션을 실행한다.
- 토큰을 파서에 반환하거나, 다음 토큰을 찾기 위해 1번으로 돌아간다.
여러 패턴을 하나의 NFA로 결합
Lex 프로그램에는 여러 개의 패턴이 있다. 예를 들어 다음과 같은 Lex 명세가 있다고 하자.
a { action₁ }
abb { action₂ }
a*b+ { action₃ }
이 세 가지 패턴을 인식하기 위해, 각 패턴에 대한 NFA를 구성한 후 하나의 결합된 NFA로 합친다.
결합 방법
- 각 패턴 pᵢ에 대해 NFA N(pᵢ)를 구성한다.
- 새로운 시작 상태 s₀를 만든다.
- s₀에서 각 N(pᵢ)의 시작 상태로 ε-전이를 추가한다.
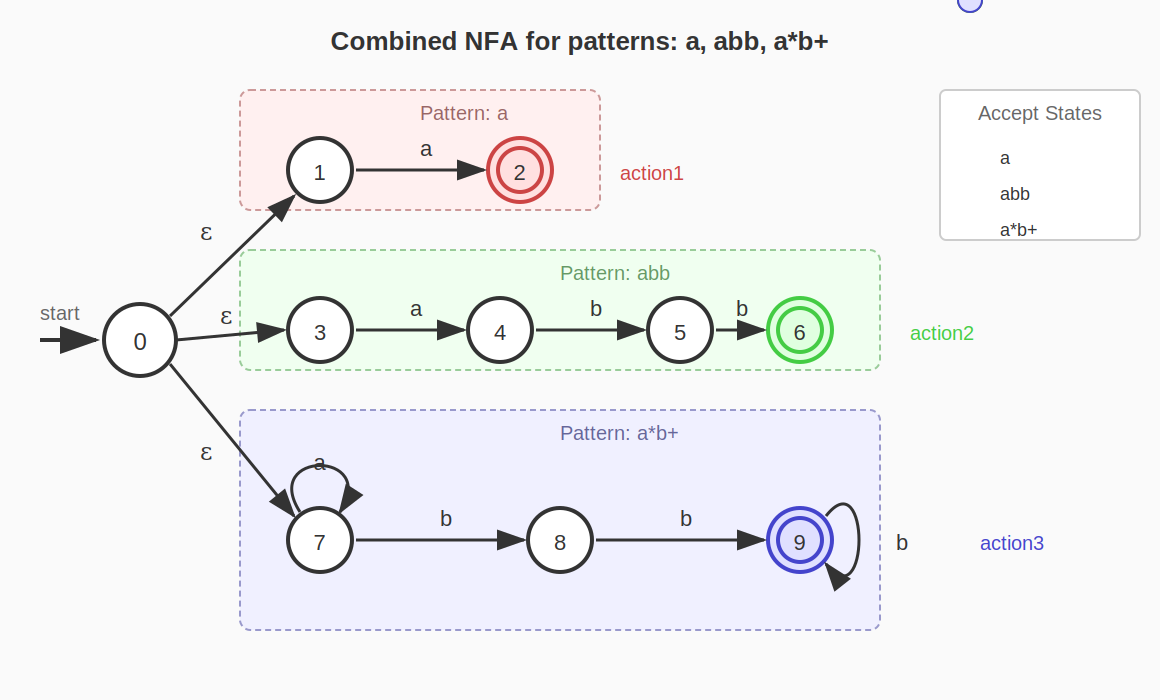
위 그림은 세 패턴 a, abb, a*b+를 결합한 NFA이다. 각 NFA의 수락 상태는 해당 패턴의 액션과 연결되어 있다.
결합된 NFA의 전이 테이블
| NFA 상태 | a | b | ε |
|---|---|---|---|
| 0 | ∅ | ∅ | {1, 3, 7} |
| 1 | {2} | ∅ | ∅ |
| 2 | ∅ | ∅ | ∅ |
| 3 | {4, 6} | ∅ | ∅ |
| 4 | ∅ | {5} | ∅ |
| 5 | ∅ | ∅ | ∅ |
| 6 | {6} | ∅ | {7} |
| 7 | ∅ | {8} | ∅ |
| 8 | ∅ | {8} | ∅ |
상태 2는 패턴 a의 수락 상태, 상태 5는 패턴 abb의 수락 상태이다.
최장 일치 규칙 (Longest Match)
어휘 분석기는 항상 가장 긴 접두사를 매칭한다. 이것을 최장 일치 규칙(Longest Match Rule) 또는 최대 뭉치 규칙(Maximal Munch) 이라고 한다.
예제: 입력 `aaba`
결합된 NFA에서 입력 aaba를 처리하는 과정을 살펴보자.
| 입력 | NFA 상태 집합 | 수락 상태 포함 여부 |
|---|---|---|
| (시작) | ε-closure({0}) = {0, 1, 3, 7} | - |
| a | {2, 4, 6, 7} | 상태 2 (패턴 a) |
| a | {2, 4, 6, 7} | 상태 2 (패턴 a) |
| b | {5, 8} | 상태 5 (패턴 abb) |
| a | ∅ | - |
네 번째 입력 a를 읽은 후 상태 집합이 공집합이 되었다. 이 시점에서 더 긴 접두사가 어떤 패턴과도 매칭될 가능성이 없다.
이제 역추적하여 수락 상태를 포함했던 마지막 상태 집합을 찾는다. 입력 aab까지 읽었을 때 상태 5(패턴 abb의 수락 상태)를 포함했으므로, 어휘항목은 aab이고 패턴 abb에 매칭된다.
최장 일치 규칙이 필요한 이유는, 예를 들어
integer라는 입력이 있을 때 키워드int가 아닌 식별자integer전체로 인식해야 하기 때문이다.
패턴 우선순위 규칙
가장 긴 접두사가 여러 패턴과 매칭될 수 있다. 이 경우 Lex는 먼저 나열된 패턴을 우선한다.
예제: 키워드와 식별자
if { return IF; }
[a-z]+ { return ID; }
입력이 if인 경우, 두 패턴 모두 길이 2의 접두사 if와 매칭된다. 이때 if 패턴이 먼저 나열되었으므로 키워드 IF 토큰이 반환된다.
입력이 ifx인 경우, [a-z]+ 패턴만 길이 3의 접두사 ifx와 매칭되므로 식별자 ID 토큰이 반환된다.
두 가지 규칙 요약
| 규칙 | 설명 |
|---|---|
| 최장 일치 | 항상 가장 긴 접두사를 매칭한다 |
| 우선순위 | 같은 길이로 여러 패턴이 매칭되면, 먼저 나열된 패턴을 선택한다 |
NFA 기반 패턴 매칭
NFA를 직접 시뮬레이션하여 패턴 매칭을 수행할 수 있다. 이 방법의 알고리즘은 다음과 같다.
S = ε-closure(s₀);
SStack = [S]; // 상태 집합의 스택
PosStack = [0]; // 입력 위치의 스택
c = nextChar();
pos = 1;
while (S != ∅) {
S = ε-closure(move(S, c));
SStack.push(S);
PosStack.push(pos);
c = nextChar();
pos++;
}
// 역추적하여 수락 상태를 찾음
while (SStack이 비어있지 않음) {
S = SStack.pop();
pos = PosStack.pop();
if (S가 수락 상태를 포함) {
입력 위치를 pos로 되돌림;
가장 먼저 나열된 패턴의 액션 실행;
return;
}
}
// 어떤 패턴도 매칭되지 않음 - 에러 처리
NFA 기반 접근법은 DFA를 명시적으로 구성하지 않아 메모리를 절약할 수 있지만, 매 입력마다 여러 상태를 추적해야 하므로 시간이 더 걸릴 수 있다.
DFA 기반 어휘 분석기
실제 Lex 구현에서는 NFA를 DFA로 변환하여 사용한다. DFA는 각 입력에 대해 정확히 하나의 상태만 추적하면 되므로 더 효율적이다.
DFA 구성
이전 포스트의 부분집합 구성법을 사용하여 결합된 NFA를 DFA로 변환한다.
| DFA 상태 | NFA 상태 집합 | a | b | 수락 패턴 |
|---|---|---|---|---|
| A | {0, 1, 3, 7} | B | C | - |
| B | {2, 4, 6, 7} | B | D | a |
| C | {8} | - | C | a*b+ |
| D | {5, 8} | - | C | abb, a*b+ |
상태 D는 패턴 abb와 a*b+ 모두의 수락 상태를 포함한다. 이 경우 먼저 나열된 abb 패턴을 선택한다.
죽은 상태 처리
DFA 구성 시 죽은 상태(dead state) 에 대한 특별한 처리가 필요하다. 어휘 분석기에서는 더 이상 어떤 수락 상태에도 도달할 수 없을 때를 알아야 한다. 죽은 상태로의 전이는 생략하고, 죽은 상태에 도달하면 역추적을 시작한다.
Lookahead 연산자
일부 토큰은 전방 탐색(lookahead) 이 필요하다. Lex에서는 / 연산자로 이를 표현한다.
DO / ({letter}|{digit})*=({letter}|{digit})*,
이 패턴은 FORTRAN의 DO 키워드를 인식한다. / 뒤의 패턴은 매칭되어야 하지만, 어휘항목에는 포함되지 않는다.
예를 들어 입력 DO 5 I = 1, 10에서:
- 전체 패턴
DO 5 I = 1,이 매칭된다. - 하지만 어휘항목은
DO만 포함한다. /뒤의 부분은 다음 토큰 인식을 위해 입력 버퍼에 남는다.FORTRAN에서는
DO5I=1,10이DO 5 I = 1, 10과 같은 의미이다.DO5I=1.10은 변수DO5I에1.10을 대입하는 것이다. 쉼표와 마침표를 구분하기 위해 상당한 전방 탐색이 필요하다.
어휘 분석기 생성기의 전체 흐름
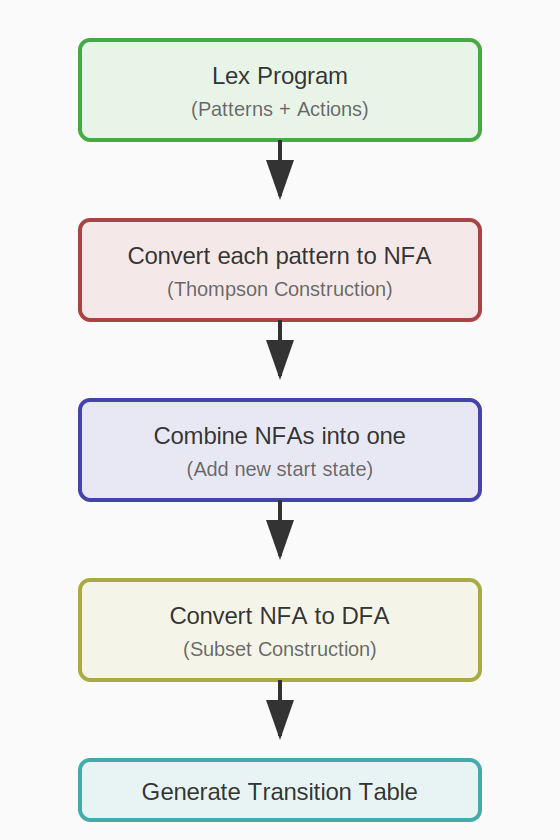
이 과정을 통해 정규 표현식 명세로부터 효율적인 어휘 분석기가 자동으로 생성된다.
실제 구현에서의 고려사항
테이블 압축
DFA 전이 테이블은 상태 수 × 입력 심볼 수 크기의 2차원 배열이다. 입력 알파벳이 크면(예: 유니코드) 테이블 크기가 매우 커질 수 있다.
실제 구현에서는 다음과 같은 기법으로 테이블을 압축한다.
- 기본값 배열: 대부분의 상태가 같은 전이를 가지면 기본값으로 저장
- 다음 상태 배열 + 체크 배열: 희소 테이블을 효율적으로 표현
- 문자 클래스: 같은 전이를 가지는 문자들을 하나의 클래스로 그룹화
에러 복구
매칭되는 패턴이 없을 때의 에러 복구 전략도 필요하다.
- 현재 문자를 출력하고 다음 문자부터 다시 시작 (가장 단순한 방법)
- 에러 토큰을 반환
- 에러 메시지 출력 후 특정 문자(예: 세미콜론)까지 건너뜀
Lex에서는 모든 패턴에 매칭되지 않는 문자를 처리하기 위해 보통 마지막에 . 패턴(임의의 문자)을 추가한다.
. { printf("Unexpected character: %c\n", yytext[0]); }