
소켓 그 다음, 웹 서버
우리는 파일 디스크립터라는 "번호표" 하나 뒤에 커널의 거대한 자료구조가 숨어있다는 것, 그리고 send()와 recv()가 결국 시스템 콜이라는 것을 알게 됐다.
그런데 실제로 , Django나 FastAPI를 배포하려고 하면, 이런 말을 듣게 된다.
"프로덕션에서는 Gunicorn이나 Uvicorn을 써야 해요." 왜?
python app.py로 실행하면 안 되나?오늘은 이 질문에 답하면서, 소켓 위에서 웹 서버가 어떻게 동작하는지 깊이 들어가 본다.
왜 개발 서버로는 안 되는가?
Flask나 Django의 개발 서버를 보자.
# Flask 개발 서버
if __name__ == '__main__':
app.run(debug=True)
내부적으로 이런 일이 일어난다:
# 단순화된 개발 서버 구조
import socket
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.bind(('0.0.0.0', 5000))
server.listen(5)
while True:
client, addr = server.accept() # 블로킹!
request = client.recv(4096) # 블로킹!
response = handle_request(request)
client.send(response)
client.close()
이전 글에서 배운 내용을 떠올려보자. accept()와 recv()는 블로킹 시스템 콜이다. 연결이 오거나 데이터가 도착할 때까지 그 스레드는 완전히 멈춘다.
문제가 보이는가? 한 클라이언트의 요청을 처리하는 동안, 다른 모든 클라이언트는 기다려야 한다. 동시 접속자가 100명이면? 99명은 줄 서서 기다린다.
2009년, Ruby 커뮤니티에서 일어난 일
이 문제를 해결하려는 시도는 오래전부터 있었다. 그중 가장 영향력 있는 해결책이 2009년 Ruby 커뮤니티에서 나왔다.
당시 Ruby 웹 서버들은 스레드 기반이었다. 요청마다 스레드를 생성하거나, 스레드 풀을 관리했다. 문제는 복잡성이었다. 스레드 동기화, 메모리 누수, 디버깅 지옥...
Eric Wong이라는 개발자가 다른 접근을 제안했다.
"Unix가 이미 다 해주는데, 왜 복잡하게 만들지?"
그가 만든 Unicorn은 fork() 시스템 콜을 핵심으로 사용했다.
// fork()의 마법
pid_t pid = fork();
if (pid == 0) {
// 자식 프로세스: 완전히 독립된 복사본
handle_requests();
} else {
// 부모 프로세스: 자식을 관리
manage_workers();
}
fork()는 현재 프로세스를 완전히 복제한다. 메모리 공간, 파일 디스크립터, 모든 것이 복사된다. 그리고 복사된 프로세스는 완전히 독립적으로 실행된다.
이게 왜 혁신적이었을까?
프로세스 격리가 공짜로 따라온다. 한 워커가 메모리 누수로 죽어도, 다른 워커는 멀쩡하다. 스레드 동기화? 필요 없다. 각 프로세스는 자기만의 메모리 공간을 가지니까.
Gunicorn의 탄생
2010년, Python 개발자 Benoit Chesneau가 Unicorn을 보고 영감을 받았다. "이거 Python에도 필요한데?"
그렇게 탄생한 것이 Gunicorn (Green Unicorn)이다. Python의 상징색인 초록색을 붙인 이름이다.
Gunicorn의 아키텍처는 Unicorn을 거의 그대로 따른다
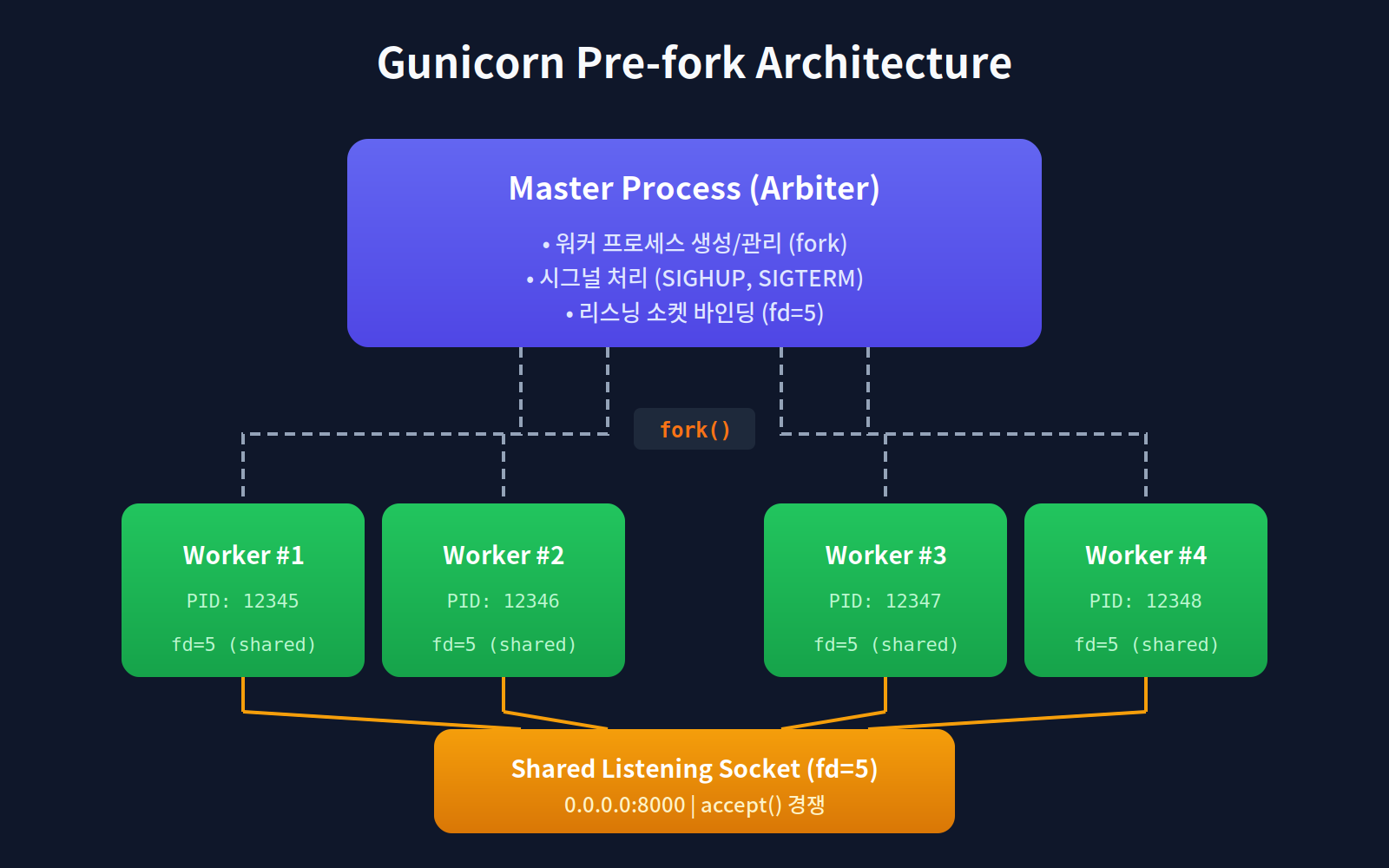
gunicorn myapp:app --workers 4 --bind 0.0.0.0:8000
1단계: 마스터가 소켓을 생성한다
# Master Process
import socket
# 리스닝 소켓 생성
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
server_socket.bind(('0.0.0.0', 8000))
server_socket.listen(2048) # backlog 설정
print(server_socket.fileno()) # 예: 5
이 시점에서 파일 디스크립터 5번이 리스닝 소켓에 할당된다.
2단계: fork()로 워커를 생성한다
import os
workers = {}
for i in range(4):
pid = os.fork()
if pid == 0:
# 자식 프로세스 (Worker)
# server_socket(fd=5)이 그대로 상속된다!
run_worker(server_socket)
sys.exit(0)
else:
# 부모 프로세스 (Master)
workers[pid] = i
print(f"Worker {pid} spawned")
핵심 포인트: fork() 이후 자식 프로세스는 부모의 파일 디스크립터를 그대로 상속받는다. 4개의 워커 프로세스가 모두 **같은 리스닝 소켓(fd=5)**을 공유하게 된다.
3단계: 워커들이 경쟁적으로 accept()한다
def run_worker(server_socket):
while True:
# 여러 워커가 같은 소켓에서 accept() 호출
# 커널이 알아서 하나의 워커에게만 연결을 전달
client, addr = server_socket.accept()
# 이 워커가 이 연결을 독점 처리
handle_request(client)
client.close()
여러 프로세스가 같은 소켓에서 accept()를 호출하면 어떻게 될까? 커널이 Thundering Herd 문제를 해결해준다. 연결이 들어오면 하나의 프로세스만 깨워서 해당 연결을 처리하게 한다.
strace로 확인하기
실제로 시스템 콜을 추적해보면:
$ strace -f -e trace=network gunicorn myapp:app --workers 2
# Master Process
socket(AF_INET, SOCK_STREAM, IPPROTO_TCP) = 5
setsockopt(5, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0
bind(5, {sa_family=AF_INET, sin_port=htons(8000), sin_addr=inet_addr("0.0.0.0")}, 16) = 0
listen(5, 2048) = 0
clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|...) = 12345 # fork
# Worker Process (PID 12345)
accept4(5, {sa_family=AF_INET, sin_port=htons(54321), ...}, [16], SOCK_CLOEXEC) = 6
recvfrom(6, "GET / HTTP/1.1\r\n...", 8192, 0, NULL, NULL) = 245
sendto(6, "HTTP/1.1 200 OK\r\n...", 1024, 0, NULL, 0) = 1024
close(6) = 0
accept4(5, ...)에서 5번 파일 디스크립터가 리스닝 소켓이고, 반환된 6번이 클라이언트 연결 소켓이다. 이전 글에서 배운 내용과 정확히 일치한다.
블로킹의 한계
Gunicorn의 기본 동기(Sync) 워커는 이런 구조다:
def handle_request(client_socket):
# 1. HTTP 요청 읽기 (블로킹)
request = client_socket.recv(8192)
# 2. 애플리케이션 로직 실행
response = app(parse_request(request))
# 3. HTTP 응답 전송 (블로킹)
client_socket.sendall(response)
문제는 2번 단계에서 발생한다. 만약 애플리케이션이 외부 API를 호출하거나 DB 쿼리를 실행한다면?
def slow_handler():
# 외부 API 호출: 500ms
data1 = requests.get("https://api.example.com/data")
# DB 쿼리: 200ms
data2 = database.query("SELECT * FROM users")
# 실제 연산: 10ms
result = process(data1, data2)
return result
총 710ms 중 700ms가 대기 시간이다. 이 700ms 동안 워커는 아무것도 하지 못한다. CPU는 놀고 있는데 프로세스는 블로킹된 상태다.
워커가 4개라면? 초당 최대 4 / 0.71 ≈ 5.6개의 요청만 처리할 수 있다.
이전 글에서 우리는 이 문제의 해결책을 이미 봤다. I/O 멀티플렉싱이다.
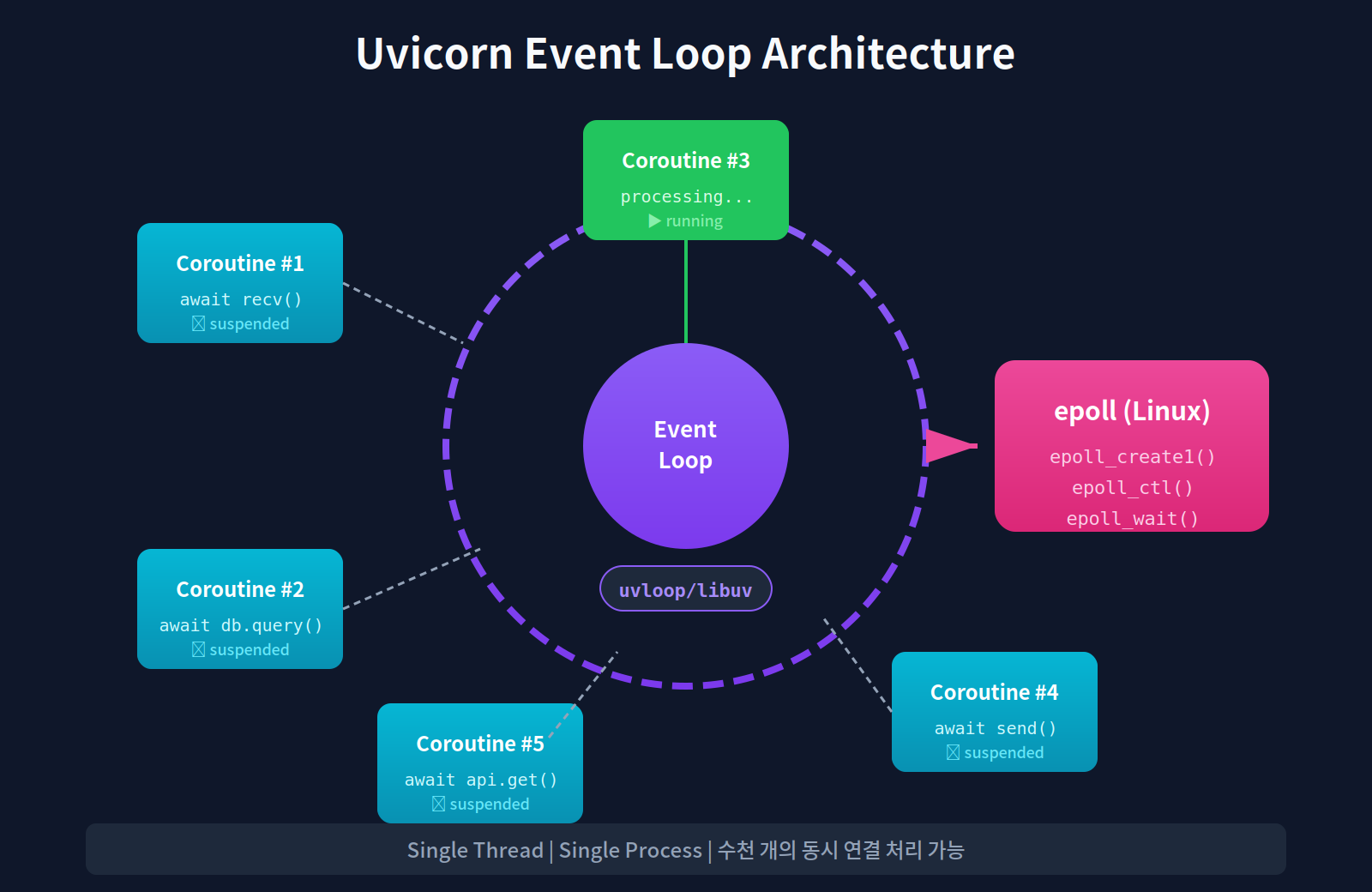
Uvicorn의 등장: epoll과 async의 만남
2017년, Tom Christie는 다른 접근을 택했다. "기다리는 시간을 낭비하지 말자."
Uvicorn은 이전 글에서 배운 epoll을 핵심으로 사용한다. 기억나는가?
epoll_wait()는 여러 소켓을 동시에 감시하다가,
이벤트가 발생한 소켓만 알려준다.
10,000개 중 10개에 이벤트가 발생하면?
select는 10,000개를 다 확인하고,
epoll은 10개만 반환한다.
Uvicorn은 이 epoll을 Python의 asyncio와 결합했다.
이벤트 루프의 실체
import asyncio
async def handle_client(reader, writer):
# 비동기로 읽기 - 데이터 없으면 다른 코루틴으로 전환
data = await reader.read(8192)
# 비동기로 처리
response = await app(parse_request(data))
# 비동기로 쓰기
writer.write(response)
await writer.drain()
writer.close()
async def main():
server = await asyncio.start_server(
handle_client, '0.0.0.0', 8000
)
await server.serve_forever()
await가 있는 지점에서 제어권이 이벤트 루프로 돌아간다. 이벤트 루프는 다른 준비된 코루틴을 실행하거나, 준비된 게 없으면 epoll_wait()로 새 이벤트를 기다린다.
uvloop: C로 작성된 고성능 이벤트 루프
Uvicorn은 기본 asyncio 대신 uvloop을 사용한다. uvloop은 Node.js가 사용하는 libuv를 Python에 바인딩한 것이다.
# Uvicorn 내부
import uvloop
asyncio.set_event_loop_policy(uvloop.EventLoopPolicy())
uvloop은 순수 Python인 asyncio보다 2~4배 빠르다. 왜? C로 작성된 libuv가 직접 epoll/kqueue를 호출하기 때문이다.
// libuv 내부 (C)
int uv__epoll_wait(int epfd, struct epoll_event* events,
int maxevents, int timeout) {
return epoll_wait(epfd, events, maxevents, timeout);
}
소켓 레벨에서 본 Uvicorn
$ strace -e trace=epoll,network python -m uvicorn myapp:app
socket(AF_INET, SOCK_STREAM|SOCK_NONBLOCK, IPPROTO_TCP) = 5
bind(5, {sa_family=AF_INET, sin_port=htons(8000), ...}, 16) = 0
listen(5, 2048) = 0
epoll_create1(EPOLL_CLOEXEC) = 6
epoll_ctl(6, EPOLL_CTL_ADD, 5, {EPOLLIN, {u32=5, ...}}) = 0
# 이벤트 루프 시작
epoll_wait(6, [{EPOLLIN, {u32=5, ...}}], 1024, -1) = 1
accept4(5, ..., SOCK_NONBLOCK) = 7
epoll_ctl(6, EPOLL_CTL_ADD, 7, {EPOLLIN|EPOLLOUT, ...}) = 0
epoll_wait(6, [{EPOLLIN, {u32=7, ...}}], 1024, -1) = 1
recvfrom(7, "GET / HTTP/1.1\r\n...", 65536, 0, NULL, NULL) = 245
sendto(7, "HTTP/1.1 200 OK\r\n...", 1024, 0, NULL, 0) = 1024
주목할 점:
- SOCK_NONBLOCK: 소켓이 논블로킹 모드로 생성된다
- epoll_create1: epoll 인스턴스 생성 (fd=6)
- epoll_ctl: 소켓을 epoll에 등록
- epoll_wait: 이벤트 대기 (여러 소켓을 동시에!)
이전 글에서 배운 epoll의 동작 방식이 그대로 보인다.
동시성 모델 비교

Gunicorn (Pre-fork, 동기)에서는 4개의 워커가 있으면, 동시에 최대 4개의 요청만 처리된다.
Uvicorn (이벤트 루프, 비동기)에서는 하나의 프로세스가 수천 개의 동시 연결을 처리할 수 있다. I/O 대기 시간을 다른 코루틴 처리에 활용하기 때문이다.
성능 차이가 극명한 시나리오
# I/O 바운드 작업: 100ms 대기
async def io_bound_handler():
await asyncio.sleep(0.1) # 외부 API 호출 시뮬레이션
return {"status": "ok"}
Gunicorn (4 workers): 초당 ~40 요청
Uvicorn (1 process): 초당 ~1000+ 요청
왜? Gunicorn은 100ms 동안 워커가 블로킹되지만, Uvicorn은 100ms 동안 다른 요청을 처리한다.
하이브리드: Gunicorn + Uvicorn
실전에서는 둘을 결합해서 사용한다:
gunicorn myapp:app \
--workers 4 \
--worker-class uvicorn.workers.UvicornWorker \
--bind 0.0.0.0:8000
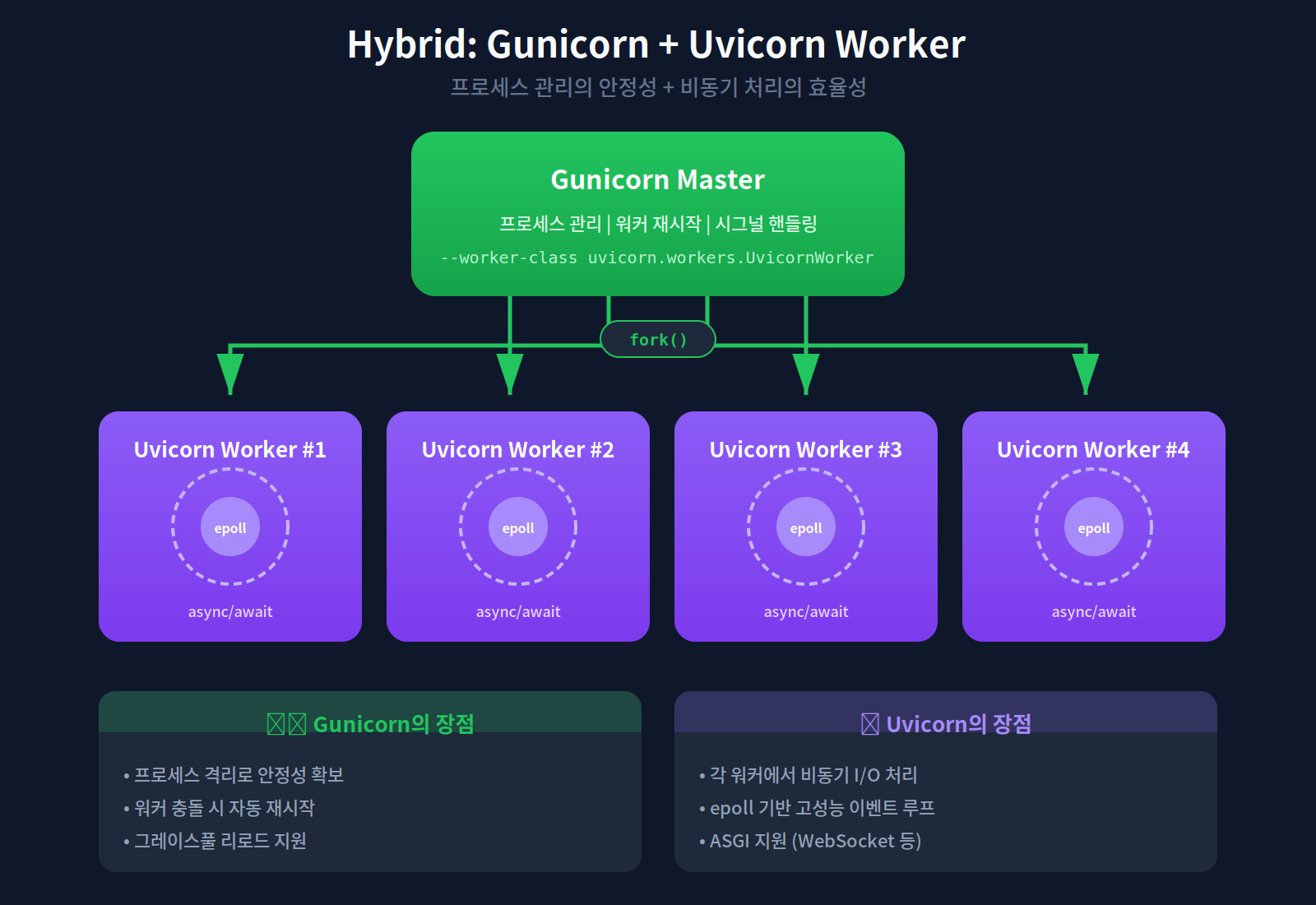
Gunicorn이 프로세스 관리의 안정성을 제공하고, Uvicorn이 각 프로세스 내에서 비동기 처리의 효율성을 제공한다. 하나의 Uvicorn 워커가 죽어도 Gunicorn 마스터가 새 워커를 spawn한다.
CPU 바운드 작업의 함정
비동기가 만능은 아니다:
async def cpu_bound_handler():
# 이미지 리사이징: CPU 100% 사용, 2초 소요
result = heavy_image_processing(image) # await 없음!
return result
이 코드에서 heavy_image_processing()은 동기 함수다. 2초 동안 이벤트 루프가 완전히 블로킹된다. 그 2초 동안 다른 모든 요청이 멈춘다.
그래서…
import asyncio
from concurrent.futures import ProcessPoolExecutor
executor = ProcessPoolExecutor(max_workers=4)
async def cpu_bound_handler():
loop = asyncio.get_event_loop()
# 별도 프로세스에서 실행, 이벤트 루프는 계속 동작
result = await loop.run_in_executor(
executor,
heavy_image_processing,
image
)
return result
CPU 집약적 작업은 별도 프로세스 풀에 위임하고, 이벤트 루프는 다른 I/O 작업을 계속 처리한다.
정리: 선택 기준
| 상황 | 권장 |
|---|---|
| 대부분 I/O 바운드 (DB, API 호출) | Uvicorn (또는 Gunicorn + UvicornWorker) |
| CPU 집약적 작업이 많음 | Gunicorn (sync worker) + 충분한 워커 수 |
| 레거시 동기 라이브러리 사용 | Gunicorn sync worker |
| 최대 안정성 필요 | Gunicorn + UvicornWorker 조합 |
| WebSocket 사용 | Uvicorn 필수 |
소켓은 커널과 애플리케이션 사이의 인터페이스다. Gunicorn은 fork()로 여러 프로세스를 만들어 각각이 독립적으로 소켓을 처리하게 한다. Uvicorn은 epoll로 하나의 프로세스가 수천 개의 소켓을 동시에 감시하며 효율적으로 처리한다.
이전 글에서 배운 accept(), recv(), send(), epoll_wait()가 웹 서버의 핵심이다. 그 위에 어떤 추상화를 얹느냐가 Gunicorn과 Uvicorn의 차이일 뿐이다.