[Python][중급] WSGI의 표준, Werkzeug 라이브러리
들어가며
Python 웹 개발을 하다 보면 WSGI, Werkzeug, Flask, Gunicorn 같은 이름들이 얽혀서 등장한다. Flask를 쓰면서도 "WSGI가 정확히 뭔지", "Werkzeug가 Flask와 어떤 관계인지"를 설명하기 어려운 경우가 많다. 이 글에서는 두 가지를 명확히 정리한다.
첫째, WSGI란 무엇인가 — 웹 서버와 Python 애플리케이션이 대화하는 표준 규약의 구조와 동작 원리를 살펴본다. 둘째, Werkzeug는 무엇을 하는가 — WSGI 표준 위에서 HTTP의 복잡한 디테일을 Python 개발자에게 익숙한 인터페이스로 감싸주는 유틸리티 라이브러리의 역할을 파헤친다.
WSGI — 웹 서버와 Python 앱 사이의 약속
WSGI가 필요한 이유
2003년 이전의 Python 웹 개발은 혼란스러웠다. 각 웹 서버마다 Python 애플리케이션을 연결하는 방식이 달랐다. Apache용으로 작성한 앱은 다른 서버에서 돌릴 수 없었고, 프레임워크마다 서버 연동 코드가 제각각이었다. 서버를 바꾸면 애플리케이션 코드까지 수정해야 하는 상황이었다.
이 문제를 해결하기 위해 2003년 PEP 333(이후 Python 3를 위해 PEP 3333으로 갱신)이 제안되었다. WSGI(Web Server Gateway Interface)는 이름 그대로, 웹 서버와 Python 애플리케이션 사이의 게이트웨이 인터페이스 표준이다.
핵심 아이디어는 단순하다. 양쪽이 지켜야 할 호출 규약(calling convention)을 하나 정하자. 서버는 이 규약대로 애플리케이션을 호출하고, 애플리케이션은 이 규약대로 응답을 반환한다. 규약만 지키면 어떤 서버와 어떤 프레임워크든 자유롭게 조합할 수 있다.
WSGI 애플리케이션의 구조
WSGI 표준이 요구하는 것은 놀라울 정도로 간단하다. 두 개의 인자를 받는 callable을 하나 만들면 된다.
def application(environ, start_response):
"""최소한의 WSGI 애플리케이션"""
# 1. environ: 요청 정보가 담긴 딕셔너리
method = environ['REQUEST_METHOD'] # 'GET', 'POST', ...
path = environ['PATH_INFO'] # '/hello'
query = environ.get('QUERY_STRING', '') # 'name=World'
# 2. start_response: 응답 상태와 헤더를 전달하는 콜백
status = '200 OK'
headers = [('Content-Type', 'text/plain; charset=utf-8')]
start_response(status, headers)
# 3. 응답 바디를 bytes의 iterable로 반환
return [b'Hello, World!']
이것이 WSGI의 전부다. 세 가지 약속만 지키면 된다.
environ 딕셔너리: 서버가 HTTP 요청 정보를 Python 딕셔너리에 담아 전달한다. REQUEST_METHOD, PATH_INFO, QUERY_STRING, HTTP_HOST, wsgi.input(요청 바디 스트림) 등 CGI 환경 변수 규약을 따르는 키들이 포함된다.
start_response 콜백: 애플리케이션이 HTTP 상태 코드와 응답 헤더를 서버에 전달하는 수단이다. start_response('200 OK', [('Content-Type', 'text/html')]) 형태로 호출한다. 이 함수는 반드시 응답 바디를 반환하기 전에 호출해야 한다.
iterable 반환값: 응답 바디는 bytes 객체의 iterable이다. 리스트, 제너레이터, 파일 래퍼 등 어떤 iterable이든 상관없다. 서버는 이 iterable을 순회하며 클라이언트에게 데이터를 전송한다.
environ 딕셔너리 들여다보기
environ에는 어떤 정보가 담기는지 실제로 확인해보자.
def debug_app(environ, start_response):
"""environ의 주요 키를 출력하는 디버그용 앱"""
lines = []
important_keys = [
'REQUEST_METHOD', # HTTP 메서드
'PATH_INFO', # 요청 경로
'QUERY_STRING', # 쿼리 스트링 (? 이후)
'CONTENT_TYPE', # 요청 바디의 타입
'CONTENT_LENGTH', # 요청 바디의 길이
'SERVER_NAME', # 서버 호스트명
'SERVER_PORT', # 서버 포트
'HTTP_HOST', # Host 헤더
'HTTP_USER_AGENT', # User-Agent 헤더
'HTTP_ACCEPT', # Accept 헤더
'wsgi.url_scheme', # 'http' 또는 'https'
]
for key in important_keys:
value = environ.get(key, '(not set)')
lines.append(f'{key}: {value}')
body = '\n'.join(lines).encode('utf-8')
start_response('200 OK', [
('Content-Type', 'text/plain; charset=utf-8'),
('Content-Length', str(len(body))),
])
return [body]
GET http://localhost:8000/hello?name=Python 요청을 보내면 다음과 같은 결과를 확인할 수 있다.
REQUEST_METHOD: GET
PATH_INFO: /hello
QUERY_STRING: name=Python
CONTENT_TYPE: (not set)
CONTENT_LENGTH: (not set)
SERVER_NAME: localhost
SERVER_PORT: 8000
HTTP_HOST: localhost:8000
HTTP_USER_AGENT: curl/8.1.2
HTTP_ACCEPT: */*
wsgi.url_scheme: http
주목할 점은 HTTP 헤더의 매핑 규칙이다. HTTP 헤더 User-Agent는 HTTP_USER_AGENT로, Accept-Language는 HTTP_ACCEPT_LANGUAGE로 변환된다. 대문자로 변경하고, 하이픈을 언더스코어로 바꾸고, 접두사 HTTP_를 붙이는 것이 CGI 규약이다. 다만 Content-Type과 Content-Length는 예외적으로 HTTP_ 접두사 없이 CONTENT_TYPE, CONTENT_LENGTH로 저장된다.
WSGI 서버의 역할
WSGI 표준은 서버 측의 책임도 명확히 정의한다. 서버가 하는 일을 의사 코드로 표현하면 다음과 같다.
# Gunicorn, uWSGI, Waitress 등이 내부적으로 수행하는 작업의 단순화
import socket
def serve(application, host='localhost', port=8000):
"""WSGI 서버의 핵심 루프 (단순화)"""
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.bind((host, port))
server_socket.listen(5)
while True:
client, addr = server_socket.accept()
raw_request = client.recv(65536).decode('utf-8')
# 1단계: HTTP 요청을 파싱하여 environ 딕셔너리 구성
environ = parse_http_to_environ(raw_request)
# 2단계: start_response 콜백 준비
response_started = False
response_headers = []
def start_response(status, headers):
nonlocal response_started, response_headers
response_started = True
response_headers = [status, headers]
# 3단계: WSGI 애플리케이션 호출
body_iterable = application(environ, start_response)
# 4단계: HTTP 응답 조립 및 전송
status, headers = response_headers
http_response = f'HTTP/1.1 {status}\r\n'
for key, value in headers:
http_response += f'{key}: {value}\r\n'
http_response += '\r\n'
client.sendall(http_response.encode('utf-8'))
for chunk in body_iterable:
client.sendall(chunk)
client.close()
서버는 네트워크 연결 관리, HTTP 파싱, environ 구성, 응답 전송이라는 인프라 작업을 담당하고, 애플리케이션은 비즈니스 로직에만 집중한다. WSGI 표준이 이 경계를 명확히 그어주는 것이다.
WSGI의 한계: 날것의 불편함
WSGI 표준은 의도적으로 최소한만 정의한다. 그래서 실제로 날것의 WSGI만으로 애플리케이션을 작성하면 금세 불편함을 느끼게 된다.
def application(environ, start_response):
method = environ['REQUEST_METHOD']
path = environ['PATH_INFO']
# 쿼리 스트링 수동 파싱
query_string = environ.get('QUERY_STRING', '')
params = {}
for pair in query_string.split('&'):
if '=' in pair:
key, value = pair.split('=', 1)
params[key] = value
# POST 바디 수동 읽기
if method == 'POST':
content_length = int(environ.get('CONTENT_LENGTH', 0))
body_raw = environ['wsgi.input'].read(content_length)
# Content-Type에 따라 파싱 방식이 달라진다
# application/json? application/x-www-form-urlencoded? multipart/form-data?
# 각각 직접 구현해야 한다...
# 경로 분기 — if/elif의 늪
if path == '/hello' and method == 'GET':
name = params.get('name', 'World')
body = f'Hello, {name}!'.encode('utf-8')
start_response('200 OK', [
('Content-Type', 'text/plain; charset=utf-8'),
('Content-Length', str(len(body))),
])
return [body]
elif path == '/users' and method == 'GET':
# ...
pass
elif path.startswith('/users/') and method == 'GET':
# URL에서 user_id 추출 — 직접 파싱
user_id = path.split('/')[-1]
# 정수 검증도 직접...
pass
# 404 처리
start_response('404 Not Found', [('Content-Type', 'text/plain')])
return [b'Not Found']
쿼리 파라미터를 수동으로 파싱하고, POST 바디를 Content-Type에 따라 각각 다르게 처리하고, URL 경로를 if/elif로 분기하고, 경로에서 변수를 직접 추출해야 한다. 엔드포인트가 늘어날수록 코드는 걷잡을 수 없이 복잡해진다.
WSGI는 "무엇을 지켜야 하는가"를 정의할 뿐, "어떻게 편하게 쓸 것인가"까지 책임지지 않는다. 바로 여기서 Werkzeug가 등장한다.
Werkzeug — WSGI 위의 유틸리티 계층
Werkzeug의 정체: 프레임워크가 아닌 도구 상자
Werkzeug(독일어로 "도구"라는 뜻)는 스스로를 **"WSGI utility library"**라고 정의한다. 이 표현에는 중요한 의미가 담겨 있다.
프레임워크는 애플리케이션의 구조를 강제한다. "이 디렉터리에 이 파일을 두고, 이 클래스를 상속하고, 이 데코레이터를 써라." 반면 Werkzeug는 어떤 구조도 강요하지 않는다. 단지 WSGI의 environ 딕셔너리를 Request 객체로 감싸주고, 응답을 Response 객체로 조립할 수 있게 해줄 뿐이다. 어떻게 조합할지는 전적으로 개발자의 몫이다.

Flask가 Werkzeug 위에 구축되었다는 사실은 유명하지만, 그 관계의 본질을 정확히 이해하는 것이 중요하다. Flask는 Werkzeug에 라우팅 규칙, 템플릿 엔진 연동, 애플리케이션 컨텍스트 같은 **구조적 의견(opinionated structure)**을 더한 것이다. Werkzeug를 이해하면 Flask의 내부 동작 원리를 이해한 것과 다름없다.
Request 객체: environ을 문명화하기
Werkzeug의 핵심 가치는 environ 딕셔너리를 Request 객체로 변환하는 데서 시작된다.
from werkzeug.wrappers import Request
def application(environ, start_response):
request = Request(environ)
# 이전: environ['REQUEST_METHOD']
print(request.method) # 'GET', 'POST', ...
# 이전: environ['PATH_INFO']
print(request.path) # '/hello'
# 이전: 쿼리 스트링 수동 파싱
print(request.args) # ImmutableMultiDict([('name', 'World')])
print(request.args.get('name')) # 'World'
# 이전: environ['wsgi.input'].read() + 수동 파싱
print(request.form) # POST 폼 데이터
print(request.json) # JSON 바디 (Content-Type이 application/json일 때)
# 이전: environ['HTTP_COOKIE'] 수동 파싱
print(request.cookies) # 쿠키 딕셔너리
# 이전: environ['CONTENT_TYPE']
print(request.content_type) # 'application/json'
Request는 environ을 감싸는 래퍼(wrapper)다. 원본 environ을 복사하거나 변형하지 않고, 프로퍼티 접근 시점에 필요한 값을 파싱한다(lazy evaluation). 따라서 Request 객체를 생성하는 비용은 거의 없다.
ImmutableMultiDict — 왜 이런 타입인가
request.args의 타입을 확인하면 ImmutableMultiDict이다. 여기에는 두 가지 설계 의도가 있다.
MultiDict인 이유: HTTP에서는 같은 이름의 파라미터가 여러 번 올 수 있다. /search?tag=python&tag=web에서 tag는 두 개다. 일반 dict로는 마지막 값만 남기 때문에, 동일 키에 복수 값을 저장할 수 있는 MultiDict가 필요하다.
# 일반 dict처럼 사용하면 첫 번째 값을 반환
request.args.get('tag') # 'python'
# 모든 값을 리스트로 가져오기
request.args.getlist('tag') # ['python', 'web']
Immutable인 이유: 요청 데이터는 클라이언트가 보낸 원본이다. 서버 측에서 실수로 수정하면 디버깅이 어려운 버그의 원인이 된다. 불변으로 만들어 이를 원천 차단한다.
request.args['tag'] = 'java' # TypeError: 불변 객체는 수정할 수 없다
파일 업로드 처리
날것의 WSGI에서 멀티파트 파일 업로드를 처리하려면 multipart/form-data 바운더리를 직접 파싱해야 한다. Werkzeug는 이를 FileStorage 객체로 추상화한다.
def upload_handler(environ, start_response):
request = Request(environ)
uploaded = request.files.get('document')
if uploaded:
print(uploaded.filename) # 'report.pdf'
print(uploaded.content_type) # 'application/pdf'
# 안전한 파일명 생성 (디렉터리 트래버설 방지)
from werkzeug.utils import secure_filename
safe_name = secure_filename(uploaded.filename)
# 저장
uploaded.save(f'/uploads/{safe_name}')
secure_filename은 ../../etc/passwd 같은 악의적 파일명에서 경로 구분자를 제거하여 디렉터리 트래버설 공격을 방지한다. 작은 유틸리티 함수지만, 보안 측면에서 매우 중요한 역할을 한다.
Response 객체: 응답 조립의 표준화
Request가 입력을 감싸는 래퍼라면, Response는 출력을 조립하는 빌더다.
from werkzeug.wrappers import Response
def application(environ, start_response):
response = Response('Hello, World!', status=200, content_type='text/plain')
# start_response 호출과 바디 반환을 Response가 대신 처리
return response(environ, start_response)
마지막 줄에 주목하자. Response 객체는 callable이며, WSGI 서버가 기대하는 start_response 호출과 iterable 바디 반환을 내부적으로 처리한다. 즉, Response 자체가 WSGI 애플리케이션의 반환값 역할을 한다.
다양한 응답을 구성하는 방법은 다음과 같다.
import json
from werkzeug.wrappers import Response
from werkzeug.utils import redirect
# JSON 응답
def json_response(data, status=200):
return Response(
json.dumps(data, ensure_ascii=False),
status=status,
content_type='application/json; charset=utf-8'
)
# 리다이렉트
def login_required(environ, start_response):
response = redirect('/login', code=302)
return response(environ, start_response)
# 헤더와 쿠키 설정
def set_session(environ, start_response):
response = Response('Logged in')
response.headers['X-Custom-Header'] = 'value'
response.set_cookie(
'session_id',
'abc123',
httponly=True, # JavaScript에서 접근 불가
secure=True, # HTTPS에서만 전송
samesite='Lax', # CSRF 방어
max_age=3600 # 1시간 후 만료
)
return response(environ, start_response)
set_cookie는 보안 관련 옵션(httponly, secure, samesite)을 명시적 파라미터로 제공한다. 날것의 WSGI에서는 Set-Cookie 헤더 문자열을 직접 조립해야 하는데, 이 과정에서 보안 속성을 빠뜨리기 쉽다. Werkzeug가 이를 파라미터화함으로써 실수를 방지한다.
URL 라우팅: Map과 Rule
웹 애플리케이션에서 URL 라우팅은 필수적이다. Werkzeug는 Map과 Rule이라는 두 가지 클래스를 통해 유연한 라우팅 시스템을 제공한다.
from werkzeug.routing import Map, Rule
from werkzeug.wrappers import Request, Response
# URL 규칙 정의
url_map = Map([
Rule('/', endpoint='index'),
Rule('/users', endpoint='user_list'),
Rule('/users/<int:user_id>', endpoint='user_detail'),
Rule('/posts/<slug>', endpoint='post_detail'),
])
# 엔드포인트 → 핸들러 함수 매핑
def on_index(request):
return Response('Welcome!')
def on_user_detail(request, user_id):
return Response(f'User #{user_id}')
view_functions = {
'index': on_index,
'user_detail': on_user_detail,
# ...
}
# WSGI 애플리케이션에서 라우팅 수행
def application(environ, start_response):
request = Request(environ)
adapter = url_map.bind_to_environ(environ)
try:
endpoint, values = adapter.match()
handler = view_functions[endpoint]
response = handler(request, **values)
except NotFound:
response = Response('Not Found', status=404)
except MethodNotAllowed:
response = Response('Method Not Allowed', status=405)
return response(environ, start_response)
Werkzeug 라우팅의 핵심적인 설계를 짚어보자. Rule은 URL 패턴 → 엔드포인트 문자열의 매핑이다. 실제 함수를 직접 참조하지 않는다. 엔드포인트 문자열에서 핸들러 함수로의 매핑은 별도의 딕셔너리(view_functions)가 담당한다. 이 간접 참조 덕분에 라우팅 규칙의 정의와 핸들러 구현을 독립적으로 관리할 수 있다. Flask의 @app.route 데코레이터가 내부적으로 이 구조를 자동화한 것이다.
컨버터(Converter)
<int:user_id>에서 int는 컨버터다. Werkzeug는 여러 내장 컨버터를 제공한다.
| 컨버터 | 설명 | 예시 패턴 | 매칭 예시 |
|---|---|---|---|
string |
기본값. 슬래시를 제외한 문자열 | <username> |
john |
int |
정수 | <int:page> |
42 |
float |
부동소수점 | <float:price> |
3.14 |
path |
슬래시를 포함한 문자열 | <path:filepath> |
docs/api/v2 |
uuid |
UUID 문자열 | <uuid:item_id> |
a1b2c3d4-... |
컨버터는 두 가지 역할을 동시에 수행한다. URL 세그먼트가 해당 타입에 맞는지 검증하고, 매칭된 값을 해당 Python 타입으로 변환한다. /users/abc는 <int:user_id> 규칙에 매칭되지 않으므로 404가 된다. user_id는 문자열이 아닌 int로 핸들러에 전달된다.
URL 빌딩 (역방향 라우팅)
adapter = url_map.bind('example.com')
url = adapter.build('user_detail', {'user_id': 42})
print(url) # '/users/42'
url = adapter.build('post_detail', {'slug': 'werkzeug-guide'})
print(url) # '/posts/werkzeug-guide'
URL을 하드코딩하지 않고 엔드포인트 이름으로 생성하면, URL 패턴을 변경해도 코드 전체를 수정할 필요가 없다. Flask의 url_for가 바로 이 Werkzeug 기능을 감싸고 있다.
미들웨어: WSGI의 합성 가능성
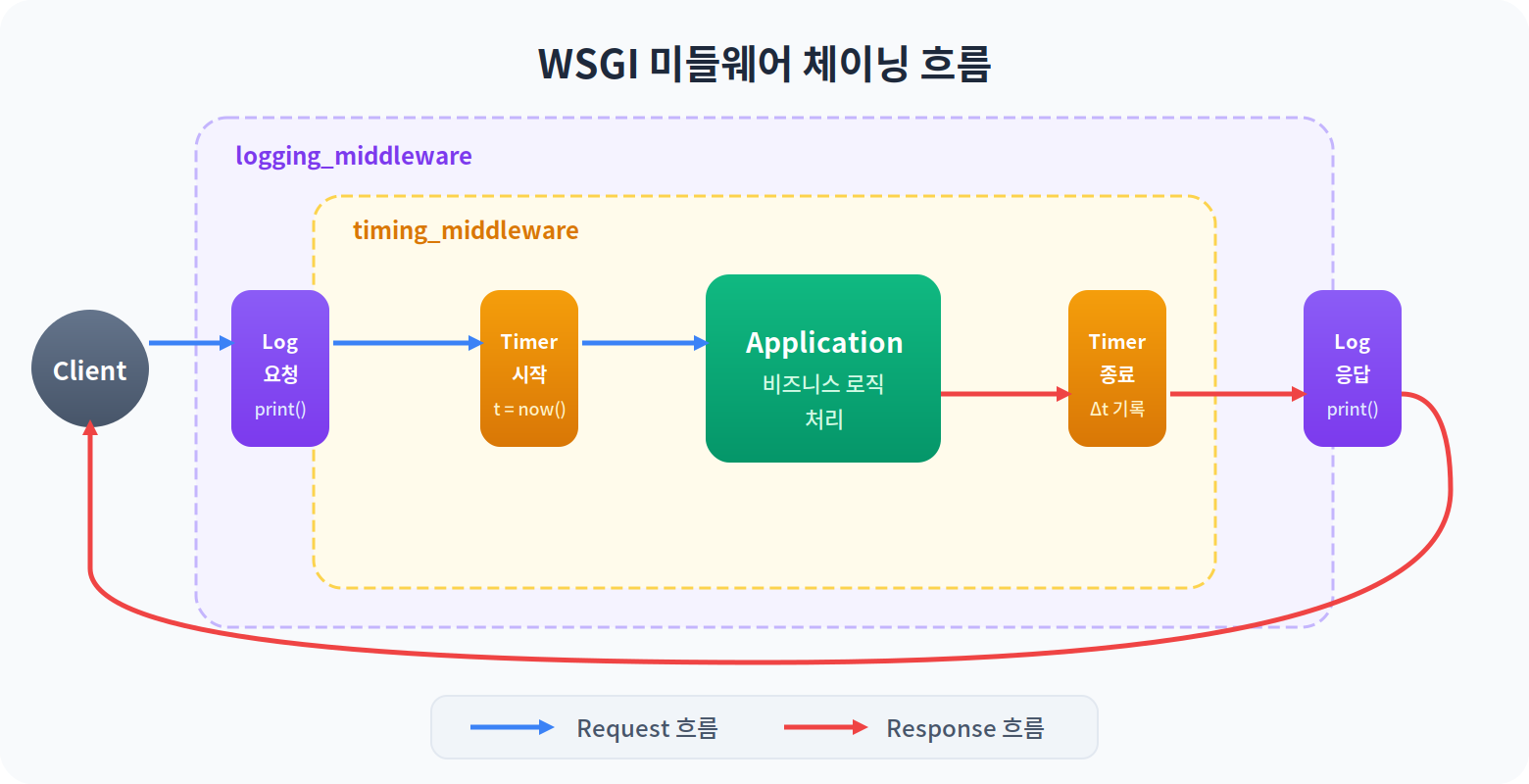
WSGI의 가장 강력한 특성 중 하나는 미들웨어 체이닝이다. WSGI 애플리케이션은 environ과 start_response를 받는 callable이므로, 애플리케이션을 감싸는 또 다른 callable을 만들 수 있다.
미들웨어의 본질을 먼저 이해하자.
# 미들웨어는 WSGI 앱을 받아 WSGI 앱을 반환하는 고차 함수다
def logging_middleware(app):
def middleware(environ, start_response):
print(f"[{environ['REQUEST_METHOD']}] {environ['PATH_INFO']}")
return app(environ, start_response)
return middleware
def timing_middleware(app):
def middleware(environ, start_response):
import time
start = time.time()
result = app(environ, start_response)
print(f"Response time: {time.time() - start:.3f}s")
return result
return middleware
# 합성: 바깥에서 안쪽으로 실행
app = logging_middleware(timing_middleware(application))
# 요청 흐름:
# Client → logging → timing → application → timing → logging → Client
각 미들웨어는 다른 미들웨어의 존재를 알 필요 없이, WSGI 인터페이스만 지키면 된다. 이것이 WSGI 표준의 합성 가능성(composability)이다.
Werkzeug는 이 패턴을 활용한 실용적인 미들웨어를 제공한다.
from werkzeug.middleware.shared_data import SharedDataMiddleware
from werkzeug.middleware.proxy_fix import ProxyFix
# 정적 파일 서빙 미들웨어
# /static/style.css 요청 → 파일 시스템에서 직접 응답
app = SharedDataMiddleware(application, {
'/static': '/path/to/static/files'
})
# 리버스 프록시 헤더 보정 미들웨어
# Nginx/ALB 뒤에서 X-Forwarded-For, X-Forwarded-Proto 반영
app = ProxyFix(application, x_for=1, x_proto=1, x_host=1)
ProxyFix는 프로덕션에서 특히 중요하다. 이 미들웨어 없이는 리버스 프록시 뒤에서 request.remote_addr이 항상 프록시의 IP를 반환하고, request.scheme이 HTTPS 환경에서도 http로 나온다.
그래서, 시각적으로 요청/응답 흐름을 보여주자면 이렇다.
디버거와 개발 서버
Werkzeug의 디버거는 예외 발생 시 브라우저에서 인터랙티브 Python 셸을 제공한다.
from werkzeug.debug import DebuggedApplication
from werkzeug.serving import run_simple
# 디버거 미들웨어 적용
app = DebuggedApplication(application, evalex=True)
# 개발 서버 실행
if __name__ == '__main__':
run_simple(
'localhost', 5000,
app,
use_reloader=True, # 코드 변경 시 자동 재시작
use_debugger=True, # 디버거 활성화
)
evalex=True로 설정하면 트레이스백의 각 프레임에서 Python 코드를 직접 실행할 수 있다. 해당 스코프의 지역 변수를 확인하고, 표현식을 평가하며, 문제의 원인을 즉석에서 파악할 수 있다. Flask의 flask run --reload와 flask run --debug가 내부적으로 이 Werkzeug 메커니즘을 사용한다.
단, 프로덕션 환경에서는 절대로 사용하면 안 된다. 원격 코드 실행(RCE) 취약점이 되기 때문이다.
세 가지 계층 비교: 날것 WSGI → Werkzeug → Flask
같은 기능을 세 가지 방식으로 구현하면, 각 계층이 정확히 어떤 복잡성을 흡수하는지 드러난다.
# ── 1. 날것의 WSGI ──
def raw_wsgi(environ, start_response):
qs = environ.get('QUERY_STRING', '')
params = dict(p.split('=', 1) for p in qs.split('&') if '=' in p)
name = params.get('name', 'World')
body = f'Hello, {name}!'.encode('utf-8')
start_response('200 OK', [
('Content-Type', 'text/plain'),
('Content-Length', str(len(body)))
])
return [body]
# ── 2. Werkzeug ──
from werkzeug.wrappers import Request, Response
def with_werkzeug(environ, start_response):
request = Request(environ)
name = request.args.get('name', 'World')
response = Response(f'Hello, {name}!', content_type='text/plain')
return response(environ, start_response)
# ── 3. Flask (= Werkzeug + 구조적 의견) ──
from flask import Flask, request
app = Flask(__name__)
@app.route('/')
def with_flask():
name = request.args.get('name', 'World')
return f'Hello, {name}!'
날것의 WSGI에서 Werkzeug로 넘어가면 environ 파싱과 응답 조립의 보일러플레이트가 사라진다. Werkzeug에서 Flask로 넘어가면 라우팅 선언, 컨텍스트 관리, 응답 변환의 보일러플레이트가 사라진다. 각 계층이 정확히 자기 몫의 복잡성을 흡수하는 것이다.
마치며
이 글에서 살펴본 내용을 정리하자.
WSGI는 웹 서버와 Python 애플리케이션 사이의 인터페이스 표준이다. environ 딕셔너리와 start_response 콜백이라는 단순한 약속으로 서버와 애플리케이션의 결합을 끊어내어, 양쪽을 자유롭게 조합할 수 있게 만들었다.
Werkzeug는 이 WSGI 표준 위에 놓인 유틸리티 계층이다. Request와 Response로 HTTP를 객체화하고, Map과 Rule로 라우팅을 구조화하며, 미들웨어와 디버거로 개발 생산성을 높인다. 프레임워크가 아니라 도구 상자이기 때문에 어떤 구조로든 조합할 수 있다.
결국 WSGI가 표준을 정의하고, Werkzeug가 그 표준을 편리하게 만들고, Flask가 그 편리함 위에 구조를 얹는다. 이 계층 구조를 이해하면 Python 웹 개발의 토대 전체가 보이기 시작한다.